دادههای پرت و شناسایی آنها در یک مجموعه داده
در دانش داده، هدف اصلی و نهایی، تصمیم گیری، اقدام یا تحلیل بر اساس دادههای اکتسابی از مطالعه موردی است. یکی از فروض اولیه و لازم برای دستیابی به موفقیت در این هدف، اطمینان از سلامت و مرتبط بودن دادههای اکتسابی است. بخش عمدهای از رفتارهایی که در طبیعت اتفاق میافتند، از الگوهای مشخصی پیروی میکنند. هدف دانش داده نیز، دستیابی به همین الگوهای پنهان از دید سطحی است. منتهی، با توجه به ماهیت دادههای اکتسابی، همیشه احتمال اکتساب همزمان دادههای غیر مرتبط نیز به همراه دادههای مرتبط وجود دارد.
به زبان ساده، همیشه مقداری از ورودیهای نامطلوب وجود دارند که منجر به افزودن پیشوند -نا- به صفت خالص میشوند. به عنوان مثال، زمانی که بین دو نفر گفتگو میشود، در کنار سیگنالهای تولیدی از تارهای صوتی این افراد، مقدار زیادی سیگنال ناشی از انواع صداهای موجود در محیط نیز وارد گوش میشود. این توانایی مغز در تشخیص و حذف دادههای غیرمرتبط است که برقراری ارتباط کلامی را در وجود شرایط نامناسب ممکن میسازد. در علوم مختلف، از عبارات مختلفی مانند نویز و دادههای پرت به جای یکدیگر استفاده میشود. در یک تعریف کلی، دادههای پرت مقادیر ثبت شدهای هستند، که با توجه به الگوهایی که نمایش میدهند، از ماهیت متفاوتی ناشی میشوند.
دادههای پرت میتوانند از عوامل مختلفی ناشی شده باشند، مانند:
اشتباهات ثبتی
اشتباهات ثبتی، مقادیر ثبت نشده به دلیل اشتباه در ثبت (خطای انسانی یا سختافزاری)، الگوهای متفاوتی را نمایش میدهند.
اشتباهات ناشی از همزمانی
اشتباهات ناشی از وقوع عوامل همزمان، اما غیر مرتبط (به دلیل همزمانی وقوع عوامل در محیط، دادههای ثبت شده منحصر از مورد تحت بررسی نیستند)
شناسایی و حذف دادههای پرت اهمیت بالایی در تحلیلهای توصیفی، مدلسازی و یادگیری ماشین دارد. پیش از هر چیز، ماهیت و نوع دادههای استخراج شده هستند که نوع رویکرد مورد استفاده در شناسایی دادههای پرت را تعیین میکنند. به صورت رایج، رویکردهای مورد استفاده در شناسایی دادههای پرت از مفاهیم آماری بهره میگیرند. خواننده، برای آشنایی با تئوری روشهای رایج در شناسایی دادههای پرت میتواند از لینکهای زیر بهره بگیرد:
https://towardsdatascience.com/a-brief-overview-of-outlier-detection-techniques-1e0b2c19e561
https://www.sciencedirect.com/topics/engineering/outlier-detection
در این مقاله، در راستای آموزش عملی داده کاوی، تلاش بر این است تا مثالی از شناسایی دادههای پرت در یک مجموعه داده فرضی با استفاده از پایتون ارائه شود.
اجرا در پایتون:
با توجه با ماهیت متفاوت زبان پایتون، کتابخانههای مختلف و مستقل برای اهداف گوناگون آماده شدهاند. یکی از مهمترین ابزارهای شناسایی دادههای پرت، کتابخانه معروف و قدرتمند Scikit Learn است. در این کتابخانه چهار روش عمده برای شناسایی دادههای پرت تعبیه شدهاند که در تصویر زیر مشخص شده است:

در ادامه، همانند مثال متلب، مجموعه دادهای تصادفی تولید و با استفاده از روش Local Outlier Factor به شناسایی دادههای پرت پرداخته شده است. در ابتدا و پس از فراخوانی کتابخانههای مورد استفاده، یک بردار از مقادیر عددی که دارای تابع ریاضی از جنس سینوسی هستند تولید میکنیم:
##### Import libraries
import numpy as np
from sklearn.ensemble import IsolationForest
import matplotlib.pyplot as plt
##### Produce data set
x = np.arange(-2*np.pi, 2*np.pi, 0.01)
Data = np.zeros(x.shape)
for i in range(len(x)):
Data[i] = np.sin(x[i])سپس، به صورت تصادفی مقادیر ۳ عدد از نمونهها را با مقادیر صفر جایگزین میکنیم:
##### Insert random outliers Idxs = np.random.choice(Data.shape[0], 3) Data[Idxs] = np.zeros(Idxs.shape)
در این مثال، از دستور IsolationForest برای شناسایی دادههای پرت استفاده میشود. در مواردی مانند این مثال که موقعیت دادههای پرت در درون بازه تغییرات قرار داشته، این تفاوت در همسایگیهاست که در شناسایی درست دادههای پرت نقش کلیدی بازی میکند. نحوه فراخوانی این دستور در زیر نمایش داده شدهاند:
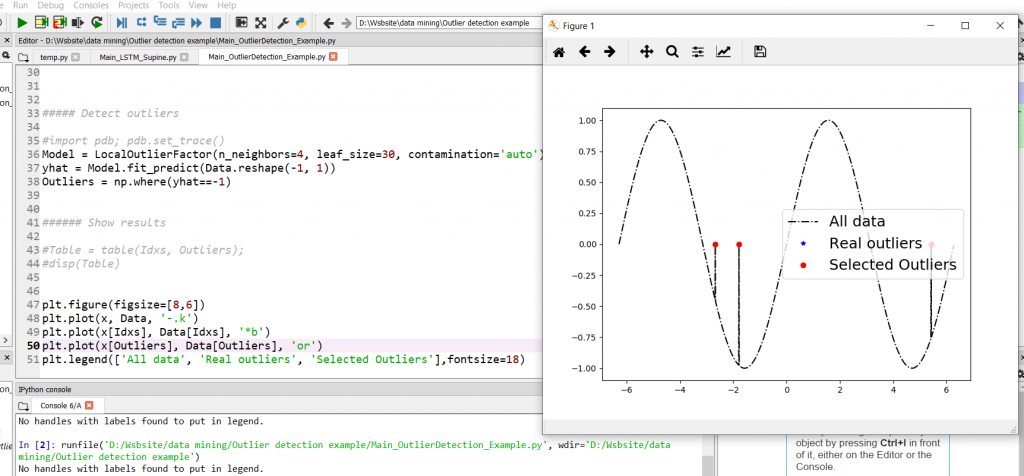
Model = LocalOutlierFactor(n_neighbors=4, leaf_size=30, contamination='auto') yhat = Model.fit_predict(Data.reshape(-1, 1)) Outliers = np.where(yhat==-1)
نتیجه حاصله در زیر آورده شده است. مشحص است که به خوبی دادههای پرت توسط دستور شناسایی شدهاند:

مهندس میلاد اشکوری
مدیر واحد R&D شرکت گیتی افروز | هوش مصنوعی در صنعت


