شناسایی حالات خواب افراد از روی سیگنالها
در این گفتار، به پیادهسازی یک نمونه از کاربرد کاوش اطلاعات سیگنال در مراقبت های پزشکی میپردازیم. هدف در این مثال، شناسایی افراد مختلف از روی حالات خواب آنها با استفاده مدل یادگیری عمیق LSTM میباشد. برای این منظور، از مجموعه داده های ارائه شده در مقاله زیر استفاده می کنیم:
https://ieeexplore.ieee.org/document/7897206
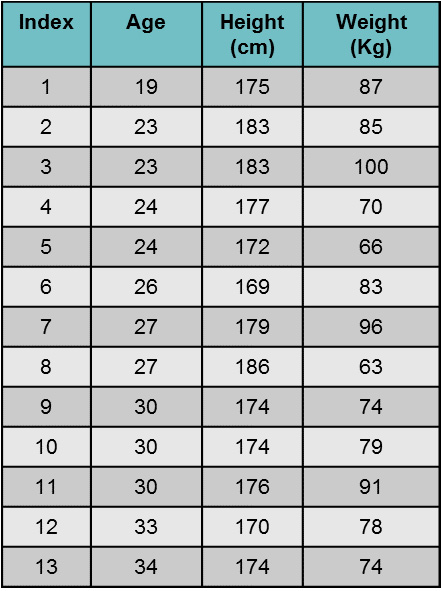
همانطور که در متن مقاله کاملا توضیح داده خواهد شد، شناسایی الگوی حالات خواب اهداف مختلف با استفاده از سیگنال Pressure Map مدنظر است. همانطور که در مقاله مرجع اشاره شده است، مجموعه داده اول با مشارکت ۱۳ نفر انجام شده است. اطلاعات این ۱۳ نفر در شکل زیر آمده است:
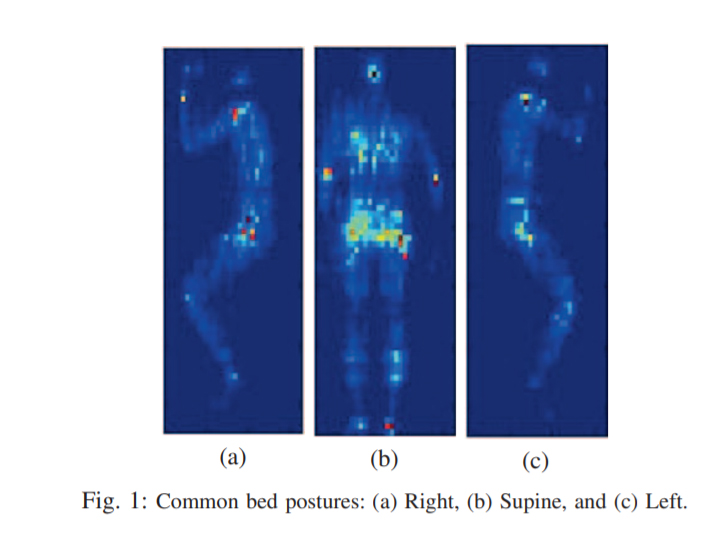
حالات خواب به سه الگوی استاندارد Right، Supine و Left تقسیم شده است:
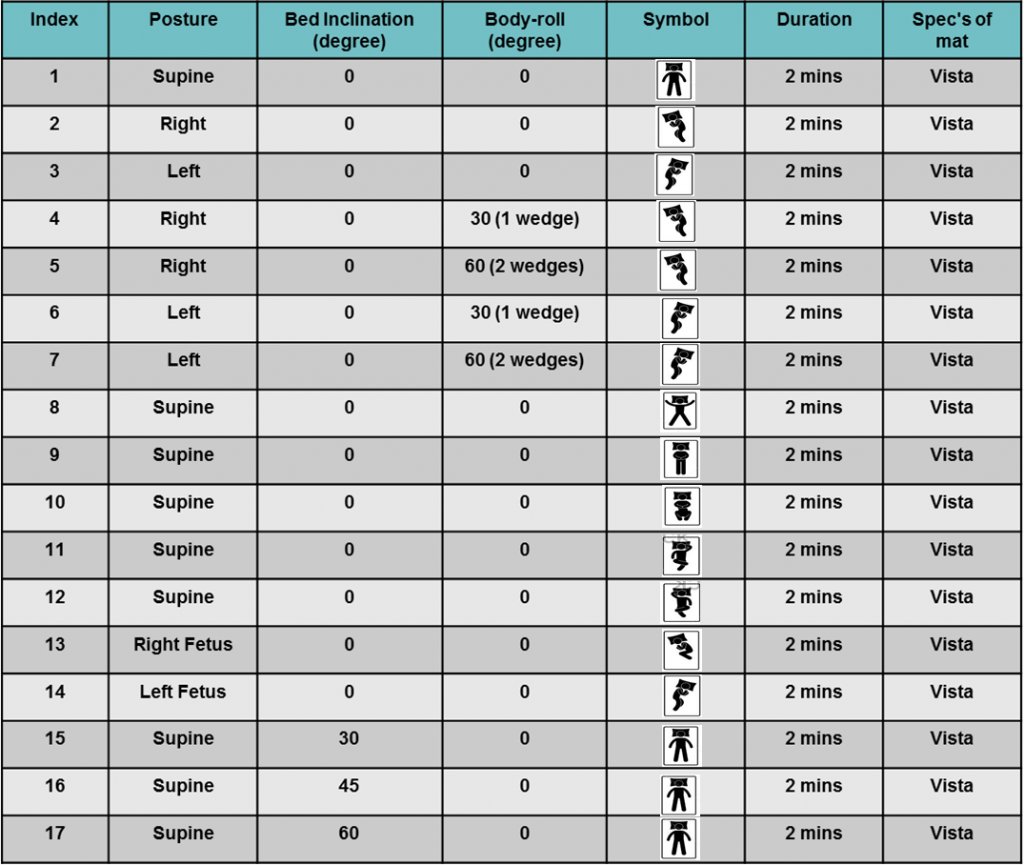
از هر نفر ۲ دقیقه در حالت آرامش کامل دیتا ثبت شده است. همچنین، برای هر نفر اقدام ثبت داده در سه حالت استاندارد خواب Supine، Left و Right دیتا به تفکیک استخراج شده است. در مجموع، برای هر شخص ۱۷ بار دیتا ثبت شده است که شکل زیر تعلق هر یک از ۱۷ رکورد را به ۳ ساحت استاندارد خواب نشان می دهد:
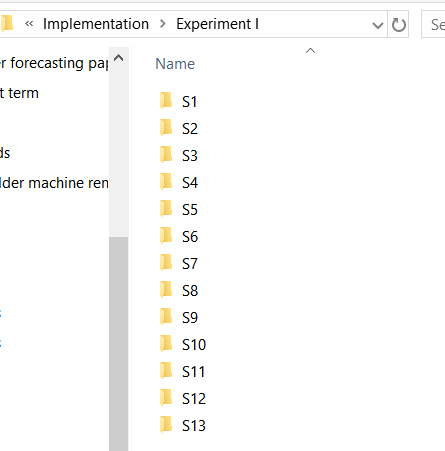
دادههای این پژوهش، در یک پوشه با عنوان Experiment I ذخیره شدهاند. درون این پوشه، ۱۳ پوشه با اسامی شکل زیر وجود دارند:
در هر پوشه نیز، سیگنال ثبت شده از هر شخص در هر یک از ۱۷ اقدام انجام شده به صورت یک فایل .txt ذخیره شده است. درون هر فایل .txt سیگنال خام که در واقع یک سیگنال دوبعدی با اندازه 64*32 بوده است، به صورت یک سیگنال 1*2048 ذخیره شده است.
هدف:
شناسایی هر یک از ۱۳ فرد از روی حالات خوابشان در حالت Left (خوابیدن به پهلوی چپ)
روش اجرا در پایتون:
پس از فراخوانی کتابخانه ها و تعریف چند تابع برای کمک به فراخوانی خودکار دادهها، آموزش شبکه LSTM با چند لایه و تست شبکه:
# -*- coding: utf-8 -*- """ Created on Thu Dec 17 00:04:41 2020 @author:Milad """ import os import numpy as np from keras.models import Sequential from keras import layers from keras.utils import to_categorical from sklearn.metrics import accuracy_score from sklearn.metrics import precision_recall_fscore_support from sklearn.model_selection import train_test_split import matplotlib.pyplot as plt from sklearn.metrics import confusion_matrix import pylab as pl from sklearn import preprocessing
########### Functions ###########
defgetFileList(directory = os.path.dirname(os.path.realpath(__file__))):
list = os.listdir(directory)
return list
def getModel(x_train, x_validation, train, validation):
#building a linear stack of layers with the sequential model
model = Sequential()
#RNN Layer
model.add(layers.LSTM(20, return_sequences=True, activation='relu', input_shape=(x_train.shape[1], x_train.shape[2])))
#flatten output of conv
model.add(layers.Flatten()) #this converts our 3D feature maps to 1D feature vectors
##Fully connected layer
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dense(64, activation='sigmoid'))
model.add(layers.Dense(13, activation='softmax'))
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
history = model.fit(x_train, train, epochs = 8, verbose = False, validation_data = (x_validation, validation), batch_ )
return model, history
def getPrediction(model, x_train, x_test, train):
model.evaluate(x_train, train, verbose = False)
predictions = model.predict(x_test)
return predictionsابتدا دادهها توسط مسیریابی و خواندن خودکار فایلها از درون پوشهها فراخوانی میشوند:
########### Load dataset
Path = 'Experiment I'
Temp1 = getFileList('Experiment I')
Inputs = []
Labels = []
L = -1
for i in range(len(Temp1)):
L+=1
temp = getFileList(os.path.join(Path, Temp1[i]))
for j in [2, 5, 6, 13]:
Temp2 = np.loadtxt(os.path.join(Path, Temp1[i], Temp[j]))
for k in range(Temp2.shape[0]):
Inputs.append(Temp2[k])
Labels.append(L)
Inputs = np.array(Inputs)
Labels = np.array(Labels)سپس، در قالب بخش پیشپردازش مقادیر عددی سیگنالها به بازه [0,1] نگاشت میشوند و در قالب بخش پارتیشنبندی، به سه بخش “آموزش”، “اعتبارسنجی” و “تست” تقسیم میشوند:
########### Pre-process # Standardization min_max_scaler = preprocessing.MinMaxScaler() Inputs = min_max_scaler.fit_transform(Inputs) ########### Partition data to train and test X_temp, X_test, y_temp, y_test=train_test_split(Inputs, Labels, test_size=0.2, random_state=42) X_train, X_validation, y_train, y_validation = train_test_split(X_temp, y_temp, test_size=0.3, random_state=42)
سپس، ابتدا مقادیر خام و دو بعدی سیگنال به صورت چهاربعدی و متناسب با الزامات ورودی شبکههای یادگیری عمیق، تغییر شکل داده میشوند. سپس، یک شبکه LSTM با ساختار نمایش داده شده در ادامه برای آموزش روی دادههای آموزش اجرا میشود:
########### Create and Train Network # Reshape data to match with network X_train = X_train.reshape(X_train.shape[0], 1, X_train.shape[1]) X_validation = X_validation.reshape(X_validation.shape[0], 1, X_validation.shape[1]) X_test = X_test.reshape(X_test.shape[0], 1, X_test.shape[1]) y_train = to_categorical(y_train) y_test = to_categorical(y_test) y_validation = to_categorical(y_validation) #Train model, history = getModel(X_train, X_validation, y_train, y_validation) print(model.summary())

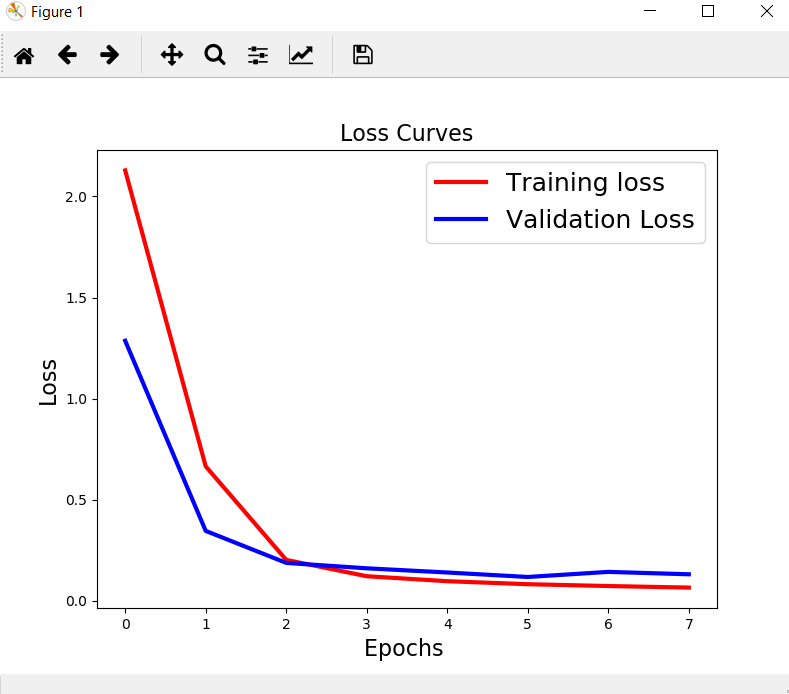
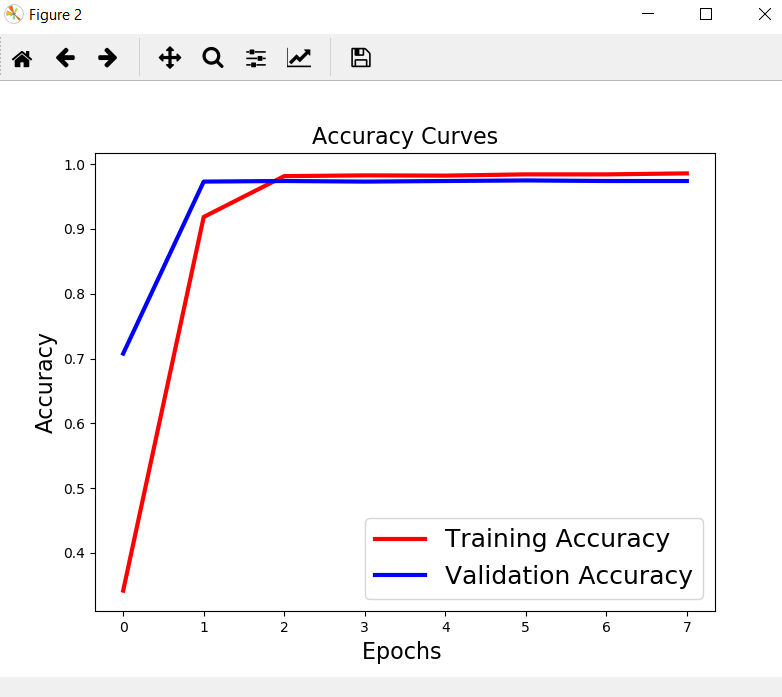
در انتها نیز، ابتدا مدل آموزش دیده روی دادههای تست اعمال شده و پس از آن ابتدا معیارهای ارزیابی دستهبندی حساب شده و پس از آن نمودارهای ماتریس درهمریختگی و فرایند تغییرات دقت و loss function در حین آموزش نمایس داده میشوند:
########### Test trained Model on test data
Temp1 = getPrediction(model, X_train, X_test, y_train)
Temp1 = np.round(Temp1)
########### Evaluate Results
result1 = precision_recall_fscore_support(y_test, Temp1)
print("Fscore:", result1[2])
print("Precision:", result1[0])
print("Recall:", result1[1])
Accuracy = accuracy_score(y_test, Temp1)
print("Accuracy:", accuracy_score(y_test, Temp1))
Precision = result1[0]
Recall = result1[1]
Fscore = result1[2]
############## Show results
# Loss Curves
plt.figure(figsize=[8,6])
plt.plot(history.history['loss'], 'r',linewidth=3.0)
plt.plot(history.history['val_loss'], 'b',linewidth=3.0)
plt.legend(['Training loss', 'Validation Loss'],fontsize=18)
plt.xlabel('Epochs',fontsize=16)
plt.ylabel('Loss',fontsize=16)
plt.title('Loss Curves',fontsize=16)
# Accuracy Curves
plt.figure(figsize=[8,6])
plt.plot(history.history['acc'], 'r',linewidth=3.0)
plt.plot(history.history['val_acc'], 'b',linewidth=3.0)
plt.legend(['Training Accuracy', 'Validation Accuracy'],fontsize=18)
plt.xlabel('Epochs',fontsize=16)
plt.ylabel('Accuracy',fontsize=16)
plt.title('Accuracy Curves',fontsize=16)
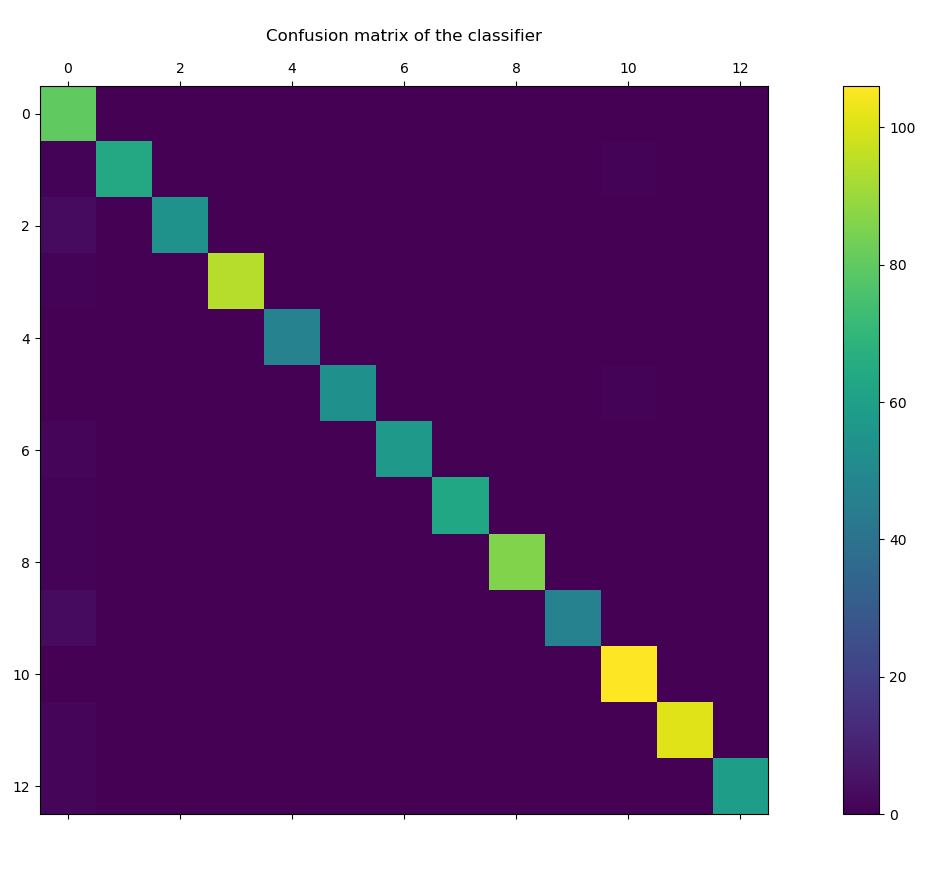
# Confusion Chart
Out_test = [np.argmax(y, axis=None, out=None) for y in Temp1]
Temp2 = y_test
y_test = [np.argmax(y, axis=None, out=None) for y in Temp2]
cm = confusion_matrix(y_test, Out_test)
Print(cm)
pl.matshow(cm)
pl.title('Confusion matrix of the classifier')
pl.colorbar()
pl.show()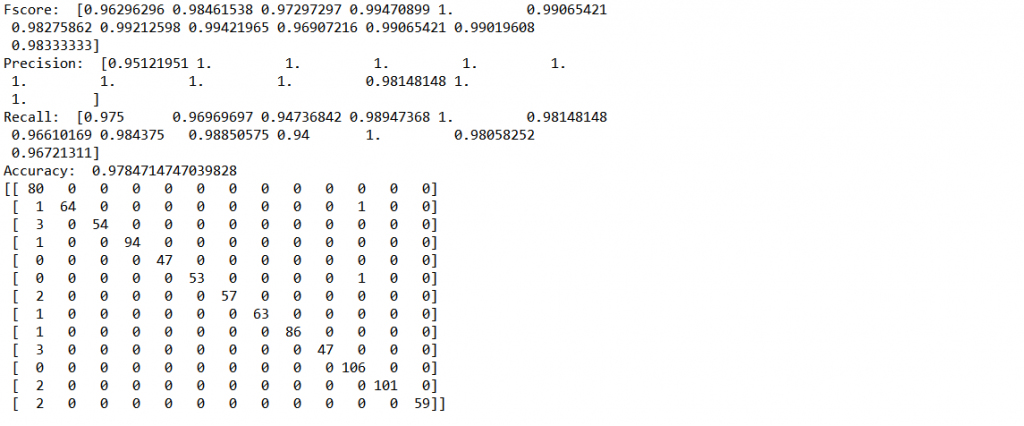

مهندس محسن عباسپور
دانشگاه صنعتی آیندهون | متخصص هوش مصنوعی قابل اعتماد | Trustworthy AI


