فرآیند آموزش در شبکه های عصبی
جهت کسب اطلاع در مورد رودمپ عمومی هوش مصنوعی روی لینک رو به رو کلیک کنید.
آموزش یادگیری عمیق
فهرست محتوا:
مقدمه
از سال ۲۰۰۶ یادگیری ساختار عمیق یا عنوان شناخته شدهتر آن به نامهای یادگیری عمیق یا یادگیری سلسلهمراتبی به عنوان حوزهی جدیدی در تحقیقات یادگیری ماشین پدیدار شد. روشها و الگوریتمهای یادگیری عمیق در چند سال اخیر توسعه چشمگیری یافت که موجب پیشرفت در مسائلی چون پردازش سیگنال و تصویر شده است. پیش از آن روشهای یادگیری عمیق و پردازش سیگنال از ساختارهای سطحی تشکیل شده بودند که تنها شامل تبدیلات ویژگی غیرخطی میشدند و از ساختار چندلایه ویژگیهای تطبیقی غیر خطی تهی بودند. روشهایی همچون مدلهای مارکف مخفی، سیستمهای پویای خطی و غیرخطی، مدلهای بیشینه آنتروپی، ماشینهای بردار پشتیبان، رگرسیون لجستیک و پرسپترون چندلایه از جمله روشهای متداول با ساختار غیر عمیق بودند که شامل تنها یک لایه برای تبدیل دادههای خام یا ویژگیها به فضای ویژگیهای خاص مسئله هستند. این روشها برای مسائل ساده بسیار مناسب هستند اما در کشف الگوهای پیچیده از مجموعه دادهای حجیم مانند تصاویر و سیگنالهای صوتی ضعیف عمل میکنند.
یادگیری عمیق با استفاده از یک الگوریتم پسانتشاری، ساختارهای پیچیده یک مجموعه داده بزرگ را کشف میکند تا نشان دهد چگونه یک ماشین میتواند پارامترهای داخلی خود را در هر لایه نسبت به لایه قبل تغییر داده و بهبود بخشد. ساختار شبکه یادگیری عمیق از بلوک نورونهای عصبی مصنوعی تشکیل شدهاست که با استفاده از توابع و معادلات ریاضی دادههای ورودی را آموزش داده و به خروجی مطلوب تبدیل میکند. با استفاده از حجم زیاد دادههای ورودی، هر نورون در تشخیص الگوهای خاص درون دادهها آموزش میبیند. یادگیری عمیق با الگو گرفتن از توانایی ذهن انسان در مشاهده، آنالیز، یادگیری و تصمیم گیری برای مسائل پیچیده به وجود آمده است.
یادگیری عمیق با دادههای خام به عنوان ورودی آغاز میشود و حالتی از آموزش انتزاعی است. آموزش انتزاعی مجموعهای از روشهاست که به ماشین اجازه میدهد دادههای خام ورودی را دریافت کرده و به صورت خودکار تمام نیازهای انتزاعی برای دستهبندی را شناسایی کند. به طور مثال وقتی یک عکس در قالب برداری از پیکسلها وارد شبکه یادگیری عمیق میشود، در لایه اول حضور یا عدم حضور لبهها در جهتگیری و مکانهای خاصی از تصویر مشخص میشود. در مرحله بعد نقوش با استفاده از ترکیب خاصی از لبهها و بدون درنظر گرفتن تغییرات کوچک در لبهها مشخص میشود. در مرحله سوم نقوش در ارتباط با بخشهای آشنای تصویر با یکدیگر ترکیب میشوند و در لایههای بعدی اجسام درون شکل به عنوان ترکیبی از این بخشها، شناسایی میشوند. یکی از جنبههای کلیدی یادگیری عمیق این است که این ویژگیها توسط انسانها طراحی نمیشوند، بلکه از خود مجموعه داده میآموزد و هدف اصلی آموزش را در نظر دارند.
برای دستهبندی تصاویر ابتدا باید مجموعهای از تصاویر با کلاسهای متفاوت را جمعآوری و ذخیره نماییم. سپس در طول مرحله آموزش یک تصویر به ماشین وارد شده و خروجی به صورت برداری از امتیازها برای هر کلاس تعیین میشود. هدف این است که کلاس مورد نظر بیشترین امتیاز را داشتهباشد. به این منظور یک تابع هدف که میزان خطا میان خروجی شبکه و کلاس مورد انتظار را محاسبه کند، در نظر گرفته میشود. سپس ماشین پارامترهای قابل تنظیم که به نام وزن شناخته میشوند را برای کاهش خطا اصلاح میکند. در یادگیری عمیق باید هزاران پارامتر و وزن تنظیم شوند. برای اصلاح مناسب بردار وزنها پس محاسبه بردار گرادیان برای هر وزن، مشخص میشود که اگر هر وزن به مقدار کمی تغییر کند چه مقدار خطا کاهش یا افزایش خواهد داشت. در نهایت بردار وزنهای موجود در جهت مخالف بردار گرادیان اصلاح میشوند.
روش های بدون نظارت
یادگیری بدون نظارت به فرآیند یادگیری ماشین بدون راهنمایی انسان گفته میشود. در این فرآیند یک مسئله که پاسخ صحیح آن را نمیدانیم به الگوریتم داده میشود. الگوریتم در طی مراحل آموزش باید پاسخ صحیح را یافته و به ما گزارش کند. تعدادی از کاربردهای روش یادگیری بدون نظارت در زیر ذکر شده است:
- یادگیری شباهتهایی که به صورت ذاتی در دادهها وجود دارند و خوشهبندی دادهها
- یادگیری ویژگیها از دادههایی که برچسب ندارند
- کاهش ابعاد داده ها
مدلهای پرکاربرد یادگیری عمیق که در گروه بدون نظارت قرار دارند، عبارتند از:
- شبکههای عصبی خود رمزنگار
- شبکههای عصبی مولد
روش های بانظارت
یادگیری با نظارت فرآیند یادگیری ماشین با راهنمایی و نظارت انسان است. در این روشها علاوه بر دادن مسئله به ماشین، جوابهای مسئله را نیز به ماشین میدهیم و در مرحله آموزش به آن یاد میدهیم تا این جوابها را برای مسئله پیدا کند. از کاربردهای این روش میتوان به دستهبندی دادهها، پیشبینی کلاس دادهها و یادگیری ویژگیها از دادههای برچسبدار، اشاره کرد. مدلهای پرکاربرد یادگیری عمیق که در گروه بدون نظارت قرار دارند، عبارتند از:
- شبکههای عصبی همگشتی
- شبکههای عصبی بازگشتی
- شبکه باور عمیق
- ماشین محدود بولتزمن
به طور کل برای ساخت هر یک از شبکههای یادگیری عمیق نیاز به طراحی نورونها و تنظیم وزنها خواهیم داشت. در طراحی یک شبکه یادگیری عمیق انتخابهای متعددی برای معماری شبکه خواهیم داشت؛ به طور مثال تعداد لایهها، تعداد پارامترها، تعداد فیلترها، تعداد نورونها، نحوه چینش و توابع تعریف شده در لایهها. برای تعیین تعداد نورونها و لایهها معمولا از کمترین مقدار ممکن ساخت شبکه را آغاز کرده و آن را آموزش میدهند و سپس در مراحل بعدی این تعداد را افزایش میدهند. این روند افزایش تا جایی که بهبودی در شبکه حاصل نشود ادامه خواهد داشت.
فرآیند آموزش در شبکههای عصبی را میتوان به صورت شکل زیر در یک فرآیند چرخشی و گام به گام تعریف کرد. دادههای اولیه وارد شبکه شده و پس از عبور از لایههای مختلف شبکه، یعنی اعمال توابع و وزنهای غیرخطی بر روی آنها، یک خروجی ایجاد میکنند. میزان اختلاف این خروجی با خروجی مطلوب ما خطا را مشخص میکند. با استفاده از این خطا، وزنها و پارامترهای شبکه اصلاح میشوند. این چرخه تا زمان رسیدن به نتیجه مطلوب ادامه خواهد یافت.

برای محاسبه نتایج، نیاز به عبور دادهها از شبکه داریم. همانطور که گفته شد عبور دادهها از شبکه به معنی اعمال وزنها و توابعیست که با عنوان توابع فعال ساز شناخته میشوند.
توابع فعالساز
تعریف سادهای که درباره توابع فعالساز وجود دارد: در اصل این تابعها قسمتی در شبکه عصبی میباشند که ورودی مقدار آنها عددی (کوچک یا بزرگ در یک بازه دلخواه) میباشد و خروجی آن به صورت بین ۰ و ۱، یا -۱ و +۱ نمایش داده میشود. در اصل این توابع مقدار ورودی دریافتی را به یک گستره مشخص (مثلا ۱- تا ۱+) انتقال میدهد. به این توابع، توابع انتقال نیز می گویند. در واقع این توابع میزان مشارکت هر نورون در شبکه عصبی را مشخص میکند. توابع فعالساز به دو گروه خطی و غیرخطی تقسیم میشوند. توابع غیرخطی بدلیل اینکه توانایی کسب ترکیبها و ویژگیهای پیچیدهتر را دارند، دامنه کاربرد بیشتری خواهند داشت. توابع غیر خطی پرکاربرد عبارتند از:
تابع فعالسازی سیگموید یا لجستیک
تابع سیگموید رفتار S شکلی مطابق شکل زیر دارد. دامنه این تابع اعداد حقیقی و برد آن از 0 تا +1 را شامل میشود. اصلیترین دلیل استفاده از این تابع فعالسازی بازه اعداد خروجی آن است. در نتیجه برای مسائلی که هدف پیشبینی مقداری احتمالی است (مانند احتمال نجات یافتن یک بیمار) بهترین گزینه است.
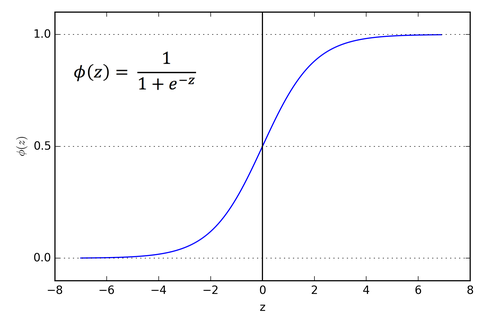
تابع فعالسازی سیگموید
این تابع مشتقپذیر است، در نتیجه میتوان در هر نقطه شیب خط مماس بر آن را یافت. تابع سیگموید به صورت رابطه زیر تعریف میشود:
تابع فعالسازی هایپربولیک تانژانت
این تابع نیز رفتاری S شکل مطابق شکل زیر دارد. دامنه این تابع نیز اعداد حقیقی است اما برد آن از -1 تا +1 را شامل میشود که نسبت به تابع سیگموید برد بیشتری را در بر میگیرد. به همین دلیل این تابع میتواند ورودیهای منفی را بهتر تصویر کند. در تحقیقات گذشته تابع هایپربولیک تانژانت نسبت به تابع سیگموید برای شبکههای پرسپترون چندلایه بهتر عمل کرده و در مقایسه به دقتهای بهتری دست یافتهاست.
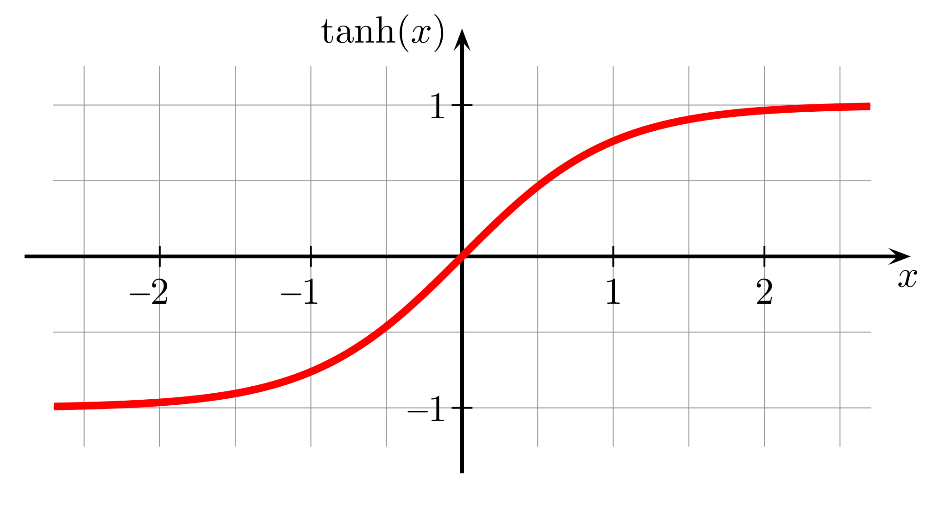
تابع فعالسازی هایپربولیک تانژانت
این تابع نیز مشتقپذیر است و به صورت زیر محاسبه میشود:
تابع فعالساز واحد یکسو شدهی خطی
از آنجاییکه تابع رلو تقریبا در تمام شبکههای عصبی همگشتی و یادگیری عمیق مورد استفاده قرار میگیرد، امروزه این تابع پرکاربردترین تابع فعالساز است. از جمله مزایای این تابع این است که تنها در ۵۰ درصد مواقع فعال میشود و در نتیجه از لحاظ پردازشی باعث صرفهجویی میشود. استفاده از تابع رلو در شبکههای تشخیص الگو و مقایسهی چهرهها موجب بهبود عملکرد شبکه شدهاست و بهتر از توابع فعالسازی باینری عمل میکند. رفتار این تابع در شکل زیر مشاهده میشود:
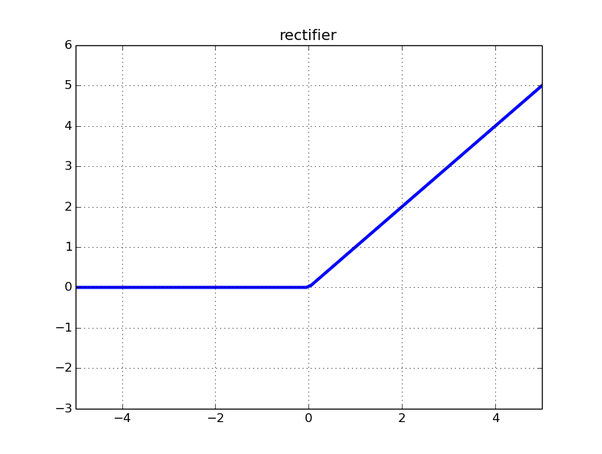
تابع فعالساز رلو
و از رابطه زیر بدست میآید:
توابع هزینه
پس از محاسبه نتایج بدست آمده از اعمال وزنها و توابع فعالساز، حال باید خروجی شبکه با مقدار مطلوب از پیش تعیین شدهای مقایسه شود. میزان انحراف از این مقدار مطلوب خطا را نشان میدهد. به طور مثال اگر دو لایه مخفی H1 و H2 به مطابق شکل زیر و تابع فعالساز f را داشته باشیم، آنگاه خروجی شبکه به صورت رابطه زیر محاسبه میشود:
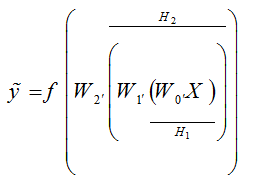
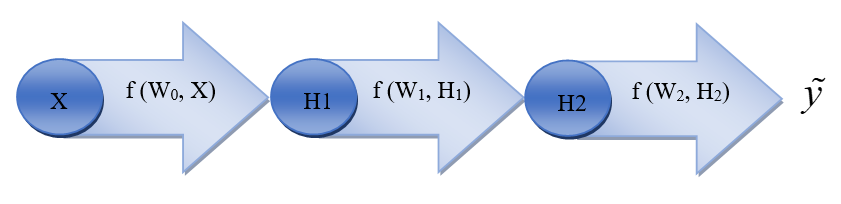
اعمال وزنها و توابع فعالساز در عبور از شبکه عصبی
اختلاف میان y و y ̃ میزان خطا را نشان میدهد. نحوه محاسبه این خطا بستگی به نوع تابع هزینه انتخاب شده دارد. به طور معمول توابعی چون میانگین مربعات خطا، کراس-آنتروپی، هینگ و سافت مکس استفاده میشوند. به طور مثال، نحوه محاسبه میانگین مربعات خطا به صورت زیر است:
یک از این توابع مذکور در مسائل خاصی کاربرد دارند به طور مثال برای مسائل رگرسیون و دستهبندی باینری بیشتر از تابع کراس-آنتروپی استفاده میشود.
توابع بهینهسازی
بعد از محاسبه خطا باید پارامترها و وزنهای شبکه برای رسیدن به خطای کمتر به روز رسانی شوند. این مرحله که بهینهسازی نام دارد در واقع حرکت قدم به قدم به سوی کمترین میزان خطاست. مقادیر خطا وابسته به پارامترهای شبکه هستند، یعنی با تغییر این پارامترها با همان ورودی اولیه به خطای متفاوتی دست خواهیم یافت.
مجموعه تمام خطاها به ازای تمام ترکیب پارامترهای ممکن برای شبکه تشکیل یک سطح ناهموار را میدهند. هدف در این مرحله دستیابی به کمترین نقطه از سطح ناهموار است. لذا با یک مسئله بهینهسازی مواجه خواهیم بود که امکان رسیدن به بهینههای محلی نیز در آن وجود خواهد داشت.
الگوریتمهای بهینهسازی که در یادگیری عمیق مورد استفاده قرار میگیرند عبارتند از: روش گرادیان نزولی تصادفی، ترکیبی از روش گرادیان نزولی تصادفی با گشتاور، روش آدام، آر.ام.اس پراپ، آداگارد و آدادلتا. روش گرادیان نزولی تصادفی اولین و معروفترین روش در مسائل یادگیری ماشین بودهاست. از دلایل محبوبیت این روش، پیادهسازی ساده و سرعت آن در مسائلی که مجموعه دادههای آموزشی بزرگی دارند، است. اما از طرف دیگر معایب استفاده از این روش، لزوم تنظیم تعداد زیادی پارامترهای بهینهسازی مانند نرخ یادگیری و تعیین معیارهای همگرایی است. از دیگر نقاط ضعف این روش این است که ذاتا متوالی بوده و نمیتوان آن را بر روی سیستمهای توزیع شده اجرا نمود. لذا روشهای دیگر با الهامگیری از آن و تلاش در رفع این نواقص ایجاده شدهاند و امروزه کاربرد بیشتری دارند.
در نهایت پس ازتعیین تابع فعالسازی و بهینهسازی باید به اصلاح وزنها در مسیر آموزش پرداخت. متداولترین روش در اصلاح وزنها روش پسانتشاری است. در این روش وزنها از آخر به اول در مسیر برگشت شبکه اصلاح میشوند. به طور مثال در شکل فوق اگر بخواهیم در مسیر برگشت وزنها را اصلاح کنیم، ابتدا وزن W2 اصلاح میشود. تابع بهینهسازی مشخص کننده نحوه اصلاح وزنها توسط تابع خطا است. فرضا اگر از روش گرادیان نزولی تصادفی استفاده کنیم وزن W2 به صورت زیر به روز رسانی میشود:
در رابطه فوق آلفا نشاندهنده نرخ یادگیری است که در حقیقت گام آموزش را نشان میدهد. شکل زیر مشکلات ناشی از انتخاب نامناسب نرخ یادگیری را نشان میدهد.
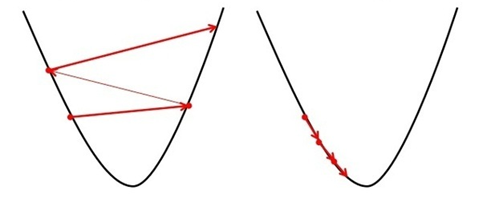
تاثیر مقادیر نامناسب نرخ یادگیری بر آموزش شبکه (الف: نرخ یادگیری بسیار کوچک. ب: نرخ یادگیری بسیار بزرگ)
نرخهای یادگیری بسیار کوچک روند آموزش را بسیار کند کرده و از سوی دیگر نرخهای آموزش بسیار بزرگ ممکن است ما را از جواب بهینه مسئله دور کنند.
اندازه ورودی
در هر مرحله از یادگیری، مدل تعدادی از نمونهها را آموزش داده و پس از آن پارامترهای شبکه تنظیم میشود به این تعداد نمونه اندازه ورودی گفته می شود. اگر اندازه ورودی برابر کل نمونه های آموزش باشد، گرادیان پایدارتر بوده و شبکه به کندی به سمت همگرایی میل می کند و از طرف دیگر اگر اندازه ورودی خیلی کوچک انتخاب گردد، گرادیان ناپایدار خواهد بود و میبایست نرخ یادگیری کاهش یابد.

تقسیم بندی تکنیک های بکارگیری داده کاوی