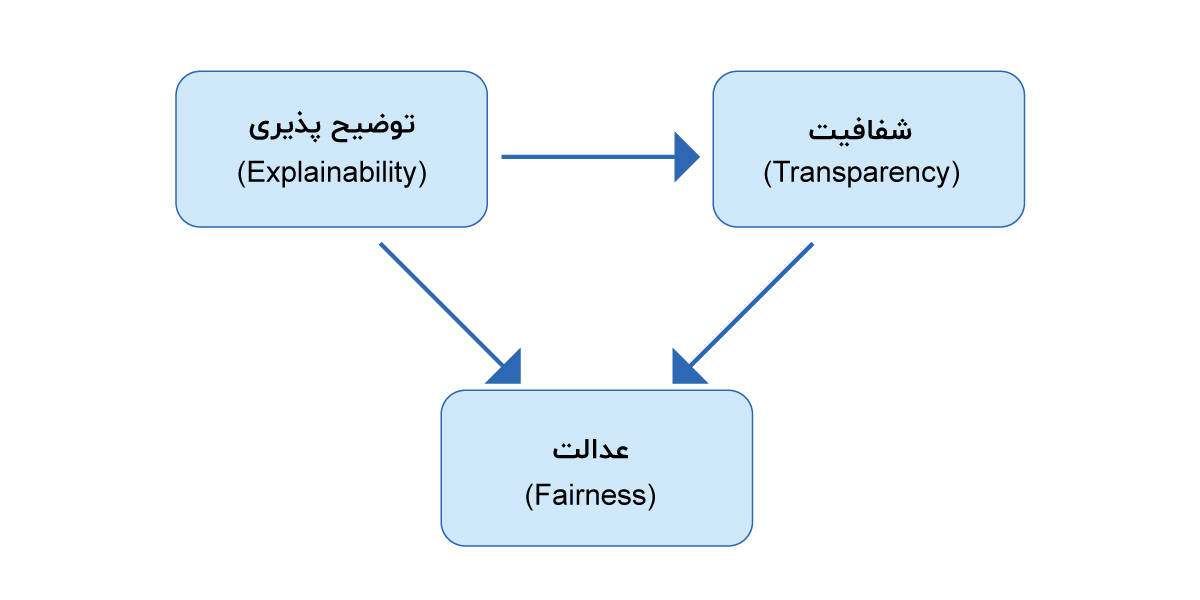
توضیح پذیری منجر به شفافیت می شود و هر دو منجر به بهبود عادلانه مدل های ML می شود.
جهت کسب اطلاع در مورد رودمپ عمومی هوش مصنوعی روی لینک رو به رو کلیک کنید.
هوش مصنوعی توضیح پذیر(XAI)
مدلهای یادگیری ماشین (ML) به طور فزایندهای در بسیاری از بخشها از جمله بهداشت و آموزش تا عدالت و تحقیقات جنایی مورد استفاده قرار میگیرند. ازاینرو، تأثیرگذاری آنها بر زندگی انسانها بیشتر و بیشتر خواهد شد. از نمونههای این تأثیرات میتوان به مدلسازی ریسک، تصمیمگیری در بیمه، آموزش (پیشبینی پیشرفت و موفقیت)، امتیازدهی اعتبار، مراقبتهای بهداشتی، تحقیقات جنایی و پیشبینی تکرار جرم و… اشاره کرد.
در تصمیمگیریهایی که نتایج آن ها نقش حیاتی در زندگی دارند مانند تشخیص بیماری، دانستن دلایل پشت چنین تصمیم مهمی بسیار حائز اهمیت است. با وجود اینکه الگوریتمهای هوش مصنوعی از نظر نتایج و پیشبینیها قدرتمند به نظر میرسند، در عین حال میتوانند مشکلساز نیز باشند زیرا به سختی میتوان بینشی در مورد مکانیسم داخلی کار آن ها، به ویژه الگوریتمهای ML بدست آورد.
این مسئله باعث بروز مشکلات بیشتری میشود، زیرا سپردن تصمیمات مهم به سیستمی که نمیتواند خود را توضیح دهد، خطرات آشکاری را به همراه دارد. شفافیت، حداقل معیاری است که کارشناسان ML میتوانند مستقیما در آن مشارکت داشته باشند و این میتواند اولین گام در این مسیر باشد.
بنابراین، طراحی سیستمهای هوشمند قابل توضیح که انتقال استدلال پشت نتایج را تسهیل میکند، در طراحی مدلهای منصفانه از اهمیت بالایی برخوردار است. معیارهای ارزیابی مرسوم مانند دقت و صحت، عادلانه بودن مدل را در نظر نمیگیرند. بنابراین، برای ارائه مدلی مطلوب، مدلهای قابل توضیح مورد نیاز است.
تحولات فعلی در هوش مصنوعی (AI) منجر به تجدید حیات هوش مصنوعی قابلتوضیح (XAI) شده است. روشهای جدیدی برای بهدستآوردن اطلاعات از سیستمهای AI بهمنظور ایجاد توضیحات برای خروجی آنها در حال تحقیق است. بااینحال، فقدان کلی ارزیابی معتبر و قابلاعتماد برای تأثیرات ایجاد شده بر تجربه کاربران و رفتار حاصل از توضیحات وجود دارد.
توضیحات مبتنی بر قانون و توضیحات مبتنی بر مثال، دو سبک توضیح نمونه هستند. نتایج نشان میدهد که توضیحات مبتنی بر قانون تأثیر مثبت کمی بر درک سیستم دارند، درحالیکه به نظر میرسد هر دو توضیح مبتنی بر قانون و توضیح مبتنی بر مثال، کاربران را در پیروی از توصیهها حتی در صورت نادرست بودن متقاعد میکنند. هیچکدام از روشهای توضیحی در مقایسه با عدم توضیح، عملکرد کار را بهبود نمیبخشد. این را میتوان با این واقعیت توضیح داد که هر دو سبک توضیحی فقط جزئیات مربوط به یک تصمیم واحد را ارائه داده و در مورد دلیل اساسی یا علیت آن نظری نمیدهد. این نتایج اهمیت ارزیابیهای کاربر را در ارزیابی مفروضات و شهود موجود در مورد توضیحات مؤثر نشان میدهد.
توجیهپذیری راه سادهای برای کاربران غیرفنی ارائه میدهد تا فرایندهای یادگیری درونی یک مدل یادگیری را درک کنند و به آنها اجازه میدهد مدل را توجیه کنند. وقتی یک مدل هوش مصنوعی توضیحپذیر میشود، کاربران را جذب میکند. در نتیجه، بهطورکلی، XAI قابلیت استفاده و مقبولیت مدلهای هوش مصنوعی موجود را بهبود میبخشد، زیرا به کاربران اجازه میدهد در فرایند اشکالزدایی و ساخت مدلها شرکت کنند.
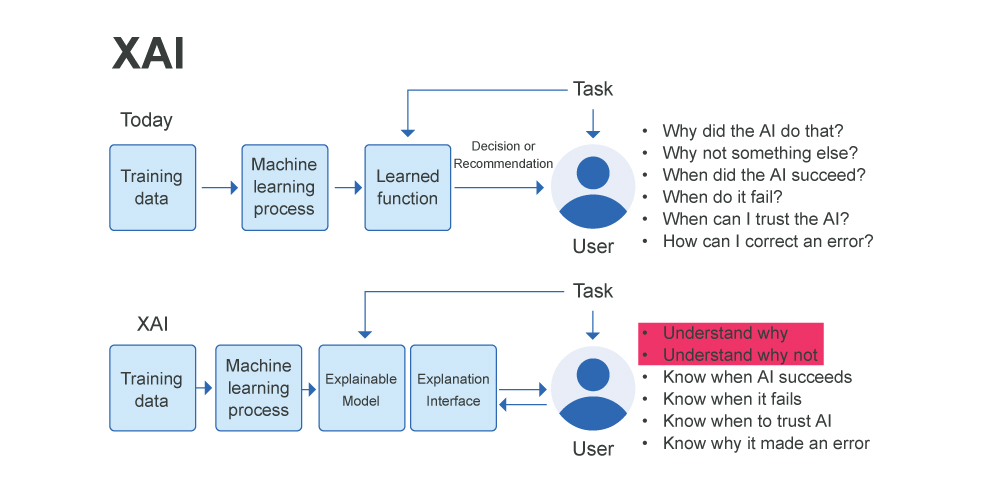
تفاوت هوش مصنوعی معمولی و هوش مصنوعی توضیح پذیر
برای استفاده ایمن از سیستمهای ML، رعایت معیارهای کمکی بسیار مهم است. بااینحال، بر خلاف معیارهای عملکرد مانند دقت، این معیارها اغلب نمیتوانند به طور کامل اندازهگیری شوند. بهعنوانمثال، ممکن است نتوانیم تمام آزمایشهای واحد موردنیاز برای عملکرد ایمن یک خودروی نیمه خودران یا همه موارد سردرگمی را که ممکن است باعث تبعیضآمیز بودن سیستم امتیازدهی اعتبار شوند، برشماریم. در چنین مواردی، یک ملاک عمومی توضیحپذیری است: اگر سیستم بتواند استدلال خود را توضیح دهد، ما میتوانیم بررسی کنیم که آیا آن استدلال با توجه به این معیارهای کمکی صحیح است یا خیر. متأسفانه، در مورد اینکه توضیحپذیری در یادگیری ماشین چیست و چگونه آن را برای محکزدن ارزیابی کنیم، اتفاقنظر کمی وجود دارد.
ارزیابی توضیحپذیری فعلی معمولاً به دودسته تقسیم میشود:
دسته اول: تفسیرپذیری را در زمینه یک برنامه ارزیابی میکند. اگر سیستم در یک برنامه کاربردی یا یک نسخه ساده شده از آن مفید باشد، پس باید به نحوی قابلتفسیر باشد.
دسته دوم: تفسیرپذیری را از طریق یک پروکسی قابلاندازهگیری ارزیابی میکند. یک محقق ممکن است ابتدا ادعا کند که برخی از کلاسهای مدل – بهعنوانمثال، مدلهای خطی پراکنده، فهرستهای قوانین، درختهای تقویتشده گرادیان – قابلتفسیر هستند و سپس الگوریتمهایی را برای بهینهسازی در آن کلاس ارائه میکنند.
مفاهیم تفسیرپذیری در بالا معقول به نظر میرسند؛ زیرا آنها با اولین آزمون اعتبار تصویری در مجموعه آزمایشی صحیح موضوعات با انسانها مواجه میشوند. بااینحال، این مفهوم اساسی بسیاری از سؤالات را بیپاسخ میگذارد: آیا همه مدلها در همه کلاسهای مدل تعریف شده برای تفسیرشدن به یک اندازه قابلتفسیر هستند؟ به نظر میرسد که پراکسیهای قابلسنجش مانند پراکندگی امکان مقایسه را فراهم میکنند، اما چگونه میتوان در مورد مقایسه یک مدل پراکنده در ویژگیها با یک مدل پراکنده در نمونههای اولیه فکر کرد؟ علاوه بر این، آیا همه برنامهها نیازهای توضیحپذیری یکسانی دارند؟ اگر میخواهیم این زمینه را به جلو ببریم – برای مقایسه روشها و درک اینکه چه زمانی ممکن است روشها تعمیم پیدا کنند، باید این مفاهیم را رسمی کنیم و آنها را مبتنی بر شواهد کنیم.
تفسیرپذیری و توضیحپذیری گاهی اوقات بهجای یکدیگر استفاده میشوند، اما مهم است که بین این دو واژه تمایز قائل شویم. تفسیرپذیری در مورد درک علت و معلول در یک سیستم هوش مصنوعی است. میزانی است که میتوانیم به طور مداوم تخمین بزنیم که یک مدل باتوجهبه یک ورودی چه چیزی را پیشبینی میکند، بفهمیم که چگونه مدل پیشبینی کرده است، بفهمیم که چگونه پیشبینی با تغییر در پارامترهای ورودی یا الگوریتمی تغییر میکند، و در نهایت، درک کنیم که مدل چه زمانی اشتباه کرده است. تفسیرپذیری عمدتاً توسط کارشناسانی قابلتشخیص است که در حال ساخت، استقرار یا استفاده از سیستم هوش مصنوعی هستند، و این تکنیکها بلوکهای سازندهای هستند که به ما کمک میکنند تا به توضیحپذیری دست پیدا کنیم.
از سوی دیگر، توضیحپذیری فراتر از تفسیرپذیری است؛ زیرا به ما کمک میکند به شکلی قابلفهم برای انسان دریابیم که یک مدل چگونه و چرا پیشبینی میکند. این مکانیک درونی سیستم را باهدف دستیابی به مخاطبان بسیار گستردهتر با عبارات انسانی توضیح میدهد. توضیحپذیری نیازمند تفسیرپذیری بهعنوان بلوک ساختمانی است و همچنین به حوزههای دیگری مانند تعامل انسان و رایانه (HCI)، قانون و اخلاق نگاه میکند.
برای ساختن یک سیستم هوش مصنوعی قابلتفسیر، باید انواع مدلهایی را که میتوانیم برای هدایت سیستم هوش مصنوعی استفاده کنیم و تکنیکهایی که میتوانیم برای تفسیر آنها به کار ببریم، درک کنیم.


مدل های جعبه سفید
مدلهای جعبه سفید ذاتاً شفاف هستند و ویژگیهایی که باعث شفافیت آنها میشود:
- درک الگوریتم مورداستفاده برای یادگیری ماشینی ساده است و میتوانیم به وضوح نحوه تبدیل ویژگیهای ورودی به متغیر خروجی یا هدف را تفسیر کنیم.
- ما میتوانیم مهمترین ویژگیها را برای پیشبینی متغیر هدف شناسایی کنیم، و این ویژگیها قابلدرک هستند.
نمونههایی از مدلهای جعبه سفید شامل: رگرسیون خطی، رگرسیون لجستیک، درختهای تصمیمگیری و مدلهای افزایشی تعمیمیافته(Generalized Additive Models) است.
مدل های جعبه سیاه
مدلهای جعبه سیاه مدلهایی با قدرت پیشبینی واقعاً بالا هستند و معمولاً در کارهایی که عملکرد مدل (مانند دقت) برای آن ها بسیار مهم است، استفاده میشوند. بااینحال، آنها ذاتاً مات هستند و ویژگیهایی که آن ها را غیرشفاف میکند شامل موارد زیر است:
- فرایند یادگیری ماشین پیچیده است و شما نمیتوانید بهراحتی درک کنید که چگونه ویژگیهای ورودی به متغیر خروجی یا هدف تبدیل میشوند.
- شما نمیتوانید به راحتی مهمترین ویژگیها را برای پیشبینی متغیر هدف شناسایی کنید.
نمونههایی از مدلهای جعبه سیاه مجموعههای درختی شامل: جنگلهای تصادفی و درختهای تقویتشده با گرادیان(Gradient-boosted trees)، شبکههای عصبی عمیق (DNN)، شبکههای عصبی کانولوشنال (CNN) و شبکههای عصبی تکراری (RNNs) هستند.

مقایسه تصویری بین مدلهای جعبه سفید و سیاه
طبقهبندی روشهای توضیحپذیری
این معیار تشخیص میدهد که آیا تفسیرپذیری با محدودکردن پیچیدگی مدل یادگیری ماشین ذاتی(intrinsic) یا با استفاده از روشهایی که مدل را پس از آموزش تحلیل میکنند (post-hoc) به دست میآید. تفسیرپذیری ذاتی به مدلهای یادگیری ماشینی اشاره دارد که به دلیل ساختار سادهشان قابلتفسیر در نظر گرفته میشوند، مانند درختهای تصمیم کوتاه یا مدلهای خطی پراکنده.
تفسیرپذیری تعقیبی به کاربرد روشهای تفسیری پس از آموزش مدل اشاره دارد. اهمیت ویژگی جایگشت، بهعنوانمثال، یک روش تفسیر پس از آموزش است. روشهای post hoc نیز میتوانند برای مدلهای قابلتفسیر ذاتی اعمال شوند. به عنوان مثال، اهمیت ویژگی جایگشت را میتوان برای درختان تصمیم محاسبه کرد.
انواع روش توضیحپذیری مدل
ابزارهای تفسیر مدل خاص(Model-specific) به کلاسهای خاصی از مدل محدود میشوند. تفسیر وزنهای رگرسیون در یک مدل خطی یک تفسیر مدل خاص است، زیرا – طبق تعریف – تفسیر مدلهای ذاتی قابلتفسیر همیشه مختص مدل است. ابزارهایی که فقط برای تفسیر به عنوان مثال شبکههای عصبی کار میکنند مدل خاص هستند.
ابزارهای مدل – آگنوستیک(Model-agnostic) را میتوان در هر مدل یادگیری ماشینی استفاده کرد و پس از آموزش مدل (post hoc) استفاده میشود. این روشهای آگنوستیک معمولاً با تجزیه و تحلیل جفتهای ورودی و خروجی ویژگی کار میکنند. طبق تعریف، این روشها نمیتوانند به اجزای داخلی مدل مانند وزن یا اطلاعات ساختاری دسترسی داشته باشند.
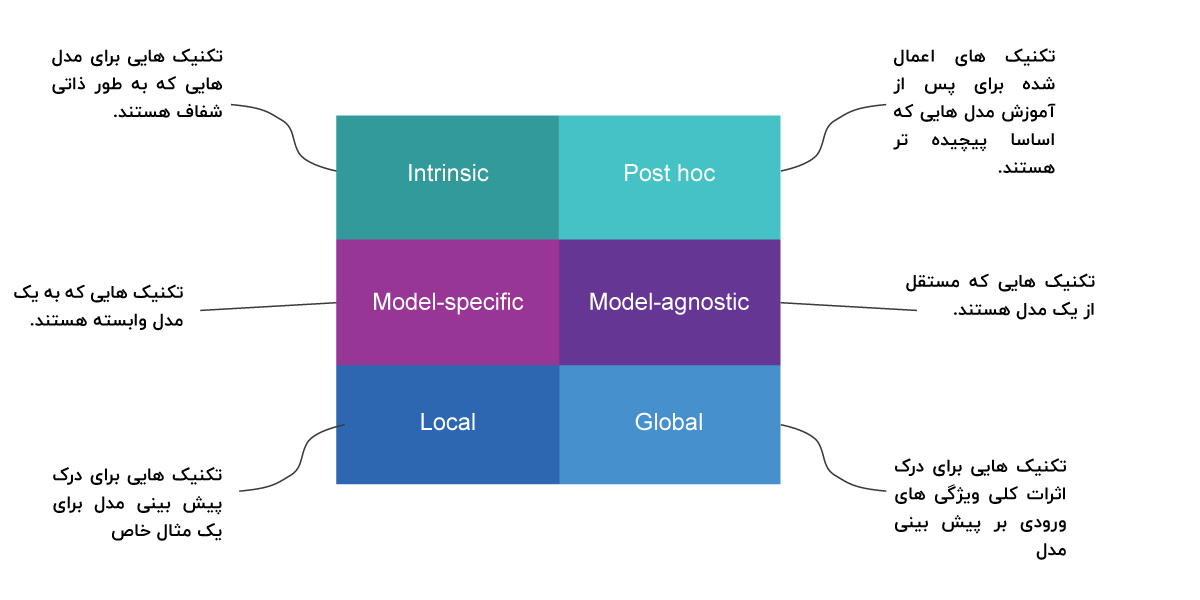
انواع تکنیک های توضیحپذیری
دامنههای توضیحپذیری مدل
تفسیر کلنگر جهانی:
شما میتوانید توضیح دهید که چگونه یک مدل پیشبینی میکند، به این دلیل که میتوانید کل مدل را به طور همزمان با درک کامل دادهها درک کنید، و این یک مدل آموزشدیده است.
تفسیر ماژولار جهانی:
همانطور که میتوانید نقش قطعات یک موتور احتراق داخلی را در کل فرایند تبدیل سوخت به حرکت توضیح دهید، میتوانید با یک مدل نیز این کار را انجام دهید. به عنوان مثال، در مثال عامل خطر CVD، روش اهمیت ویژگی ما به ما میگوید که ap_hi (فشارخون سیستولیک)، سن، کلسترول و وزن بخشهایی هستند که بیشترین تأثیر را بر کل دارند. اهمیت ویژگی تنها یکی از بسیاری از روشهای تفسیر ماژولار جهانی است، اما مسلماً مهمترین آن است.
تفسیر تک پیشبینی محلی:
میتوانید توضیح دهید که چرا یک پیشبینی واحد انجام شده است. میتوانید روی یک نمونه بزرگنمایی کنید و آنچه را که مدل برای این ورودی پیشبینی میکند بررسی کنید و توضیح دهید که چرا. اگر به یک پیشبینی فردی نگاه کنید، رفتار مدل پیچیدهتر ممکن است خوشایندتر رفتار کند. بهطور محلی، پیشبینی ممکن است فقط بهصورت خطی یا یکنواخت به برخی ویژگیها بستگی داشته باشد، نه اینکه وابستگی پیچیدهای به آنها داشته باشد. به عنوان مثال، ارزش یک خانه ممکن است به طور غیرخطی به اندازه آن بستگی داشته باشد. اما اگر فقط به یک خانه ۱۰۰ متر مربعی خاص نگاه می کنید، این احتمال وجود دارد که برای آن زیر مجموعه داده، پیش بینی مدل شما به صورت خطی به اندازه بستگی دارد. شما می توانید با شبیه سازی نحوه تغییر قیمت پیش بینی شده با افزایش یا کاهش اندازه ۱۰ متر مربع به این موضوع پی ببرید. بنابراین توضیحات محلی می توانند دقیق تر از توضیحات جهانی باشند.
تفسیر پیشبینی گروه محلی:
همان پیشبینی تک است، با این تفاوت که در مورد گروههای پیشبینی اعمال میشود. روشهای توضیح فردی را میتوان در هر نمونه استفاده کرد و سپس برای کل گروه فهرست یا جمع کرد.