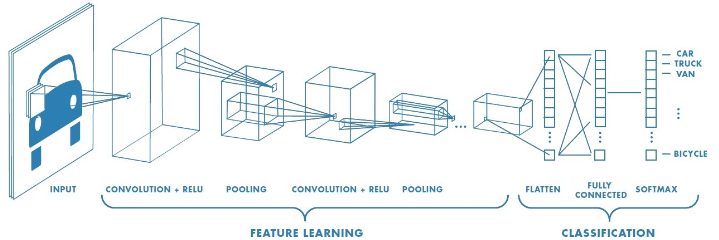
معماری ساده CNN برای طبقه بندی
جهت کسب اطلاع در مورد رودمپ عمومی هوش مصنوعی روی لینک رو به رو کلیک کنید.
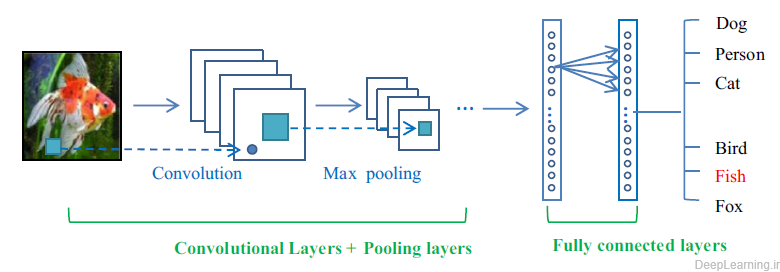
شبکه های عصبی همگشتی (CNN)
فهرست محتوا:
اولین نمونه موفق شبکههای عصبی همگشتی شبکهای با عنوان لی نت که در دهه ۹۰ معرفی گردید است. این شبکه برای تشخیص اعداد و کاراکترهای دستنویس مورد استفاده قرار گرفتهاست. ساختار شبکههای عصبی همگشتی از سازمان قشر بصری در حیوانات الهام گرفته است. ویژگیهای این شبکهها، آنها را از سایر شبکههای یادگیری عمیق متمایز میکند. اولین ویژگی لایههای همگشتی و لایههای کاهش اندازه است. برخلاف شبکههای عصبی کاملا متصل که در هر لایه تمام نورونها به نورونهای لایه بعدی متصل میشوند، در لایههای همگشتی تنها قسمتی از نورونهای یک لایه به یک نورون از لایه بعد متصل میشود. همچنین در لایههای کاهش اندازه تنها اندازه ورودی پس از عبور از این لایه کاهش مییابد.
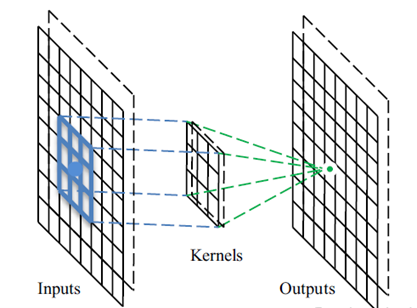
ویژگی دیگر این شبکهها، استفاده از وزنهای پنجرهای است که با عنوان فیلتر یا کرنل شناخته میشوند. این پنجرهها بر روی تمام سطح ورودی میلغزند و با اسکن کردن ورودی به ازای هر نقطه، یک نقطه از خروجی را نتیجه میدهند. این عمل مطابق شکل زیر با کانوالو شدن دو ماتریس در هم صورت میگیرد.
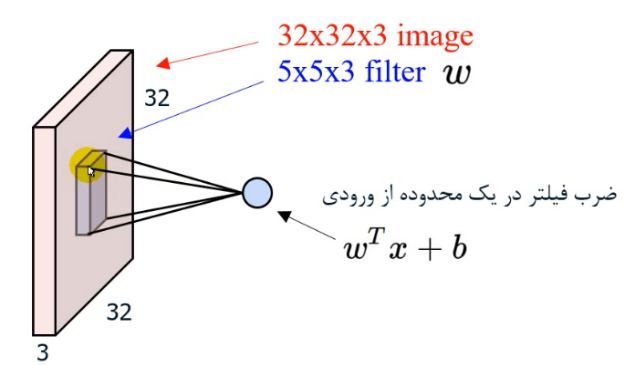
لایه همگشتی
در لایههای همگشتی هر پیکسل از تصویر ورودی همانند نورونها در لایه ورودی شبکه عصبی عمل میکند. اگر خروجیهای حاصل از هر فیلتر را به صورت دو بعدی کنار هم قرار دهیم، مجددا یک تصویر حاصل میشود. از این عمل در پردازش تصویر نیز استفاده میشود. به طور مثال شکل زیر دو نمونه از فیلترهای پنجرهای و تصاویر حاصل از اعمال آنها بر روی تصویر اصلی مشاهده میشود.
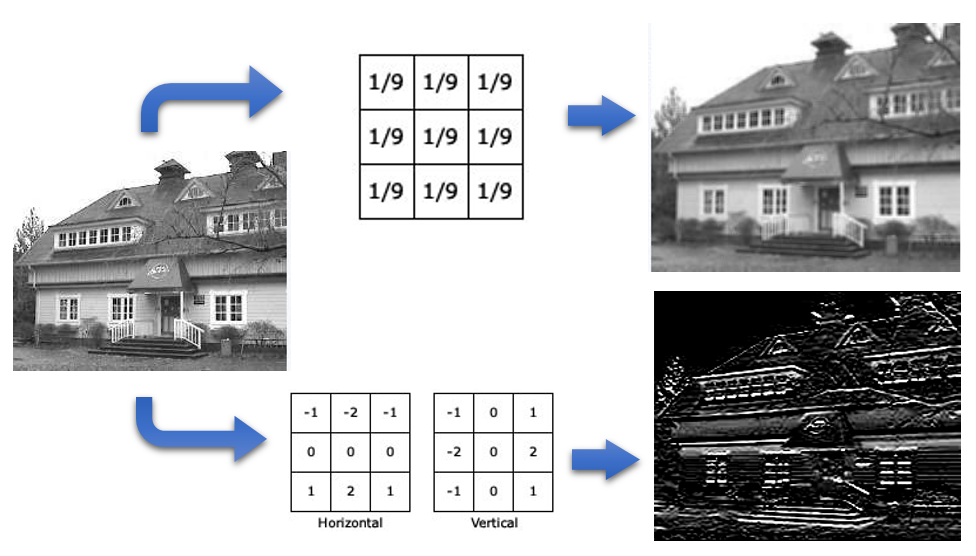
نتایج فیلترهای میانگین و سوبل بر روی یک تصویر
فیلتر بالایی در شکل فوق میانگین همسایگیهای هر پیکسل را به جای آن پیکسل قرار میدهد که در نتیجه این عمل تصویر بلور میشود. فیلتر پایینی از اعمال همزمان دو فیلتر افقی و عمودی برای تشخیص لبهها استفاده کرده است که به فیلتر سوبل در پردازش تصویر شناخته میشود.
آخرین ویژگی متمایز کننده این شبکه استفاده از چند فیلتر در یک لایه است که موجب ایجاد چند خروجی برای هر لایه میشود. هرچه تعداد فیلترهای مورد استفاده بیشتر باشد، دید ما نسبت به دادههای ورودی چندوجهیتر میشود اما از طرفی نیز با افزایش تعداد فیلترها، بار محاسباتی شبکه افزایش یافته و ممکن است قابلیتهای شبکه از دست برود. به همین دلیل در شبکههای همگشتی از لایههای کاهش اندازه استفاده میشود. این لایهها به طور کلی به دو گروه تقسیم میشوند. گروه اول، لایههایی هستند که در حین انجام عملیات همگشتی با در نظر گرفتن یک گام جهشی برای لغزیدن بر روی تصویر اولیه، باعث کاهش داده خروجی میشوند. در گروه دوم، از لایههای کاهش اندازه بعد از لایههای همگشتی استفاده میشود. این لایهها صرفا اندازه دادهها را با رویکردهایی مشخص کاهش میدهند. معروفترین رویکرد، روش مکس پولینگ است که در سال ۱۹۹۸ برای بهبود شبکهی لی-نت مورد استفاده قرار گرفت. در این رویکرد تنها بیشینه مقدار موجود از تصویر حاصل که در پنجره با ابعاد تعریف شدهی لایه کاهش اندازه قرار گرفته باشد، به لایه بعدی منتقل میشود.
در نهایت، ساختار شبکههای همگشتی برای دادههای تصویری بسیار مناسب هستند چون ساختار آنها به صورتی است که میتوان ورودی را به صورت تصویر و هر لایه را نیز تصاویر حاصل از ورودیها، در نظرگرفت. به طور کل در هر شبکه همگشتی لایههای کارکردی اصلی شامل لایههای همگشتی، فعالساز، کاهش اندازه، کاملا متصل و پیشبینی است.
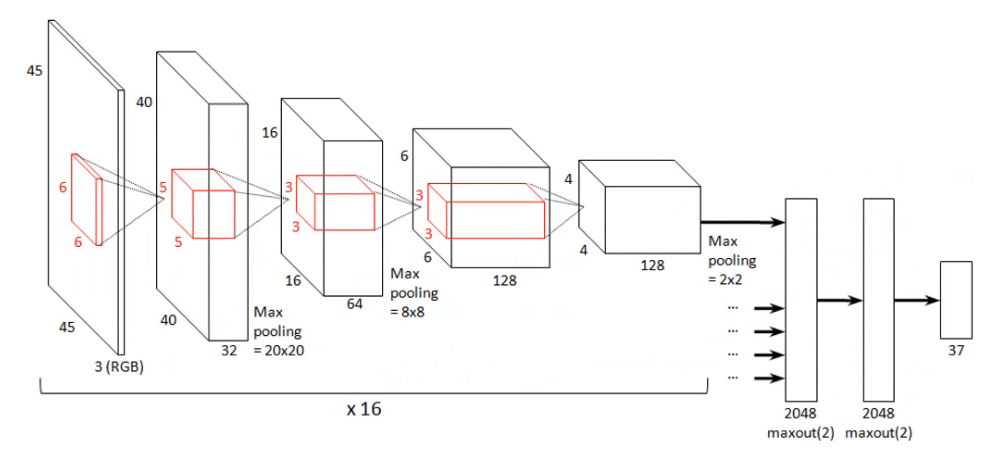
ساختار یک شبکه همگشتی
در شکل فوق ساختار یک شبکه همگشتی مشاهده میشود که از لایههای همگشتی، کاهش اندازه و اتصال کامل تشکیل شدهاست.
کاربردهای شبکههای همگشتی را میتوان در سه گروه اصلی که در شکل زیر نمایش داده شده است، تقسیم کرد. اولین کاربرد دستهبندی تصاویر است.کاربرد دوم شناسایی اجسام است. در این گروه از مسائل میخواهیم چندین شی را در تصویر با مکان حدودی آنها شناسایی کنیم. آخرین گروه از کاربردهای این شبکه بخشبندی تصویر است. در اینگونه مسائل محل دقیق هر جسم مشخص و تصویر کلی به چند بخش مجزا بر اساس اجسام تشکیل دهنده آن، افراز میشود.
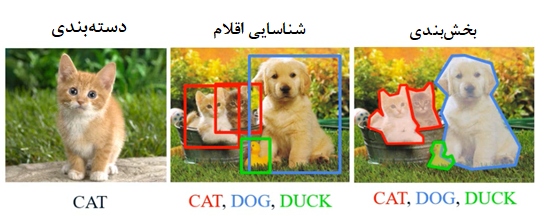
کابردهای شبکههای عصبی همگشتی
انواع لایههای شبکه عصبی همگشتی
در حالت کلی، یک شبکه عصبی همگشتی یک شبکه عصبی سلسله مراتبی است که لایه های همگشتی آن بصورت یک در میان در ارتباط با لایههای پولینگ بوده و بعد از آنها تعدادی لایه اتصال کامل وجود دارد.
لایه های یک شبکه عصبی همگشتی
۱. لایه همگشتی
در این لایهها، شبکه همگشتی از هسته های مختلف برای همگشت کردن تصویر ورودی و همینطور نشانه گذاری ویژگی های میانی استفاده می کند و این گونه ویژگی های مختلفی همانند آنچه در شکل زیر نشان داده شدهاست ایجاد می کند. انجام عملیات همگشتی سه فایده دارد:
- مکانیزم اشتراک وزن در هر نشانهگذاری وزنی که باعث کاهش شدید تعداد پارامترها می شود.
- اتصال محلی، ارتباط بین پیکسلهای همسایه را یاد می گیرد.
- باعث تغییر ناپذیری و ثبات نسبت به تغییر مکان شئ می شود.
به همین جهت امروزه در شبکههای یادگیری عمیق از لایه های همگشتی به عنوان جایگزینی برای لایههای اتصال کامل استفاده میشود تا با این کار سرعت فرآیند یادگیری افزایش یابد.
یکی از روشهای جالب توجه در مدیریت لایههای همگشتی، روش شبکه در شبکه است که در آن ایده اصلی جایگزینی لایه همگشتی با یک شبکه عصبی پرسپترون کوچک است که شامل چندین لایه اتصال کامل با توابع فعالسازی غیرخطی است. به این ترتیب فیلترهای خطی با شبکههای عصبی غیرخطی جایگزین می شوند. این روش باعث بدست آوردن نتایج خوبی در دسته بندی تصاویر میشود.
عملیات لایه همگشتی
۲. لایه پولینگ
یک لایه پولینگ معمولا بعد از یک لایه همگشتی قرار میگیرد و از آن برای کاهش اندازه وزنها و پارامترهای شبکه میتوان استفاده کرد. همانند لایههای همگشتی، لایههای پولینگ به خاطر در نظر گرفتن پیکسلهای همسایه در محاسبات خود، نسبت به تغییر مکان حساس نیستند. پیاده سازی لایه پولینگ با استفاده از تابع مکس پولینگ و تابع پولینگ میانگین رایج ترین پیادهسازی ها هستند. در شکل زیر نمونهای از فرایند مکس پولینگ مشاهده می گردد. با استفاده از فیلتر مکس پولینگ دو گامی با اندازه 2*2 یک نقشه ویژگی با اندازه 8*8 یک خروجی با اندازه 4*4 را ایجاد می کند.
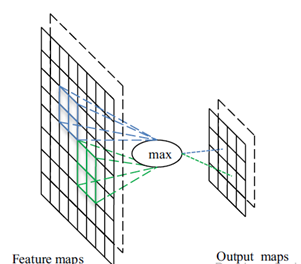
عملیات max pooling
لایههای پولینگ از میان سه لایه شبکههای همگشتی، لایههایی هستند که بیشترین میزان مطالعه روی آنها انجام شده است. بورئو و همکاران تحلیل نظری دقیقی از کارایی مکس پولینگ و پولینگ میانگین ارائه دادند و نتیجه گرفتند که مکس پولینگ میتواند باعث همگرایی سریع تر، تعمیم بهتر و انتخاب ویژگیهای بسیار عالی شود. از دیگر توابع پولینگ معروف می توان به تابع پولینگ تصادفی، پولینگ هرمی فضایی و پولینگ اریب اشاره کرد.
۳. لایه اتصال کامل
بعد از آخرین لایه پولینگ همانطور که در شکل زیر مشاهده می شود، لایههای اتصال کامل وجود دارند که مشخصه های دو بعدی را به بردارهای ویژگی یک بعدی نگاشت می کنند. لایههای اتصال کامل همانند همتایان خود در شبکه های عصبی مصنوعی سنتی عمل میکنند و تقریبا ۹۰% پارامترهای یک شبکه همگشتی را شامل می شوند. لایه اتصال کامل به کاربر اجازه میدهد تا نتیجه شبکه را در قالب یک بردار با اندازه مشخص ارائه نماید. مشکل بزرگ این نوع لایه ها این است که دارای تعداد بسیار زیادی پارامتر هستند که نتیجه این امر هزینه پردازشی بسیار بالایی است که در زمان آموزش بایستی صرف شود.
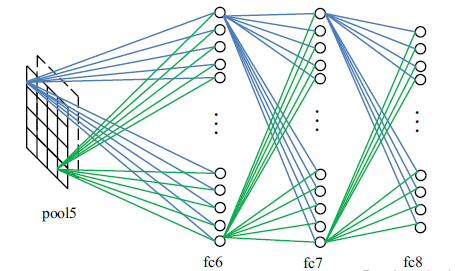
عملیات لایههای اتصال کامل
بخش بندی معنایی تصاویر
بخش بندی معنایی تصویر که به آن دسته بندی در سطح پیکسلی نیز گفته میشود، فرآیند جداسازی و تفکیک بخش هایی از تصویر میباشد که به یک دسته متعلق هستند. به عبارتی هر پیکسل از تصویر در یک کلاس مشخص طبقه بندی میگردد. بخش بندی معنایی در مواردی مانند تشخیص علائم رانندگی در جاده ها در سیستمهای پیشرفته دستیار رانندگی، بخش بندی پوششهای مختلف زمین در علم زمین شناسی و طراحی رباتهای هوشمند خودران کاربرد دارد. همچنین در زمینه های پزشکی مانند تشخیص اجزای مغز، تومورها، وسایل جراحی در اتاق عمل و طراحی رباتهای دستیار جراح نیز مورد استفاده قرار میگیرد. با پیشرفت شبکه های عصبی عمیق، روش های سنتی پردازش تصویر معنایی با سرعت زیادی بهبود یافته اند.
بخشبندی نمونه یک مفهوم کاملا مرتبط با تشخیص شی است. با این حال، بر خلاف روش تشخیص شی خروجی یک ماسک یا کانتور حاوی شی به جای یک کادر محصور کننده است. بر خلاف تقسیمبندی معنایی، تمام پیکسل ها را بخش بندی نمیکنیم؛ بلکه هدف تنها پیدا کردن مرزهای اشیا خاص در تصویر میباشد.
بخش بندی پانوپتیک ترکیبی از بخشبندی معنایی و بخش بندی نمونه ای است. هر پیکسل یک کلاس تعیین میشود (به عنوان مثال شخص)، اما اگر چندین مورد از یک کلاس وجود داشته باشد، ما میدانیم که کدام پیکسل به کدام نمونه از کلاس تعلق دارد. در شکل زیر انواع روش های بخش بندی پیکسلی تصاویر نمایش داده شده است.
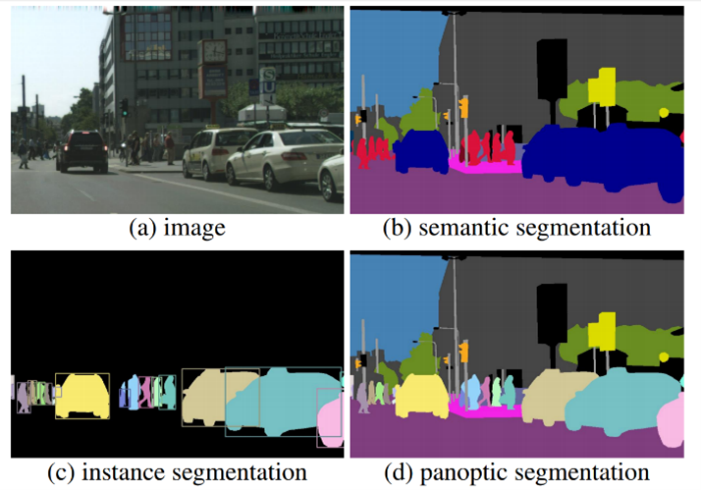
انواع روش های بخش بندی پیکسلی تصاویر
شاخص های ارزیابی عملکرد در بخش بندی معنایی تصویر
برای ارزیابی عملکرد روش های بخش بندی معنایی، عموما از شاخص های ذیل استفاده می گردد، در این روابط منظور از تعداد پیکسل های بخش i که در بخش j طبقهبندی می شوند و تعداد بخشهای مختلف موجودی در تصویر می باشد.
شاخصهای ارزیابی عملکرد بخشبندی معنایی
نام شاخص: دقت پیکسلی
توضیحات: نسبت تعداد پیکسل های صحیح دسته بندی شده به کل پیکسل ها
فرمول:
نام شاخص: میانگین دقت دسته ها
توضیحات: میانگین دقت تمام دسته ها در کل دیتاست
فرمول:
نام شاخص: میانگین وزن دار دقت دسته ها
توضیحات: میانگین وزن دار دقت تمام دسته ها در کل دیتاست
فرمول:
معماری های مختلف شبکه های عصبی همگشتی
در این بخش مدلهای متداول را مورد مطالعه قرار میدهیم و سپس خصوصیات هریک را در کاربردهای آنها بصورت خلاصه عنوان میکنیم.
شبکه الکس یک معماری قابل توجه برای شبکه عصبی همگشتی است که شامل ۵ لایه همگشتی و سه لایه اتصال کامل است. این معماری تصاویر با اندازه 224*224*3 را به عنوان ورودی دریافت کرده و سپس با انجام عملیاتهای همگشتی و پولینگ پی در پی و نهایتا ارسال نتایج به لایههای اتصال کامل، تصویر ورودی را مورد پردازش قرار میدهد. این شبکه بر روی مجموعه داده معروف شبکه تصویر آموزش دیده است.
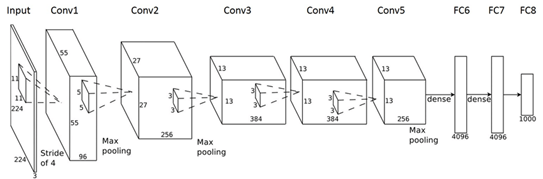
معماری شبکه الکس
اما این معماری بر اساس پژوهشهای گذشته دو مشکل بزرگ دارد که عبارتند از:
۱. این معماری نیازمند تصاویر ورودی با اندازه ثابت است.
۲. هیچ درک درستی از اینکه چرا این معماری به این خوبی کار میکند وجود ندارد.
در سال ۲۰۱۳ زیلر، روش نمایش بصری نوینی را معرفی کرد که با استفاده از آن امکان مشاهده فعالیتهای صورت گرفته درون لایههای یک شبکه عصبی همگشتی ایجاد شد. این نمایشهای بصری به آنها اجازه داد تا معماری کلاریفای که عملکرد به مراتب بهتری ازمعماری الکس نت داشتند را پیدا کرده و مدل طراحی شده آنها بالاترین کارایی را در رقابت با الکس نت بدست آورد.
هی و همکاران برای حل محدودیت نیاز به یک رزولوشن ثابت برای تصاویر ورودی هم یک استراتژی پولینگ جدید به نام شبکه پولینگ هرمی فضایی ارائه کردند تا به این وسیله محدودیت اندازه تصویر را از بین ببرند. معماری شبکه پولینگ هرمی فضایی به دست آمده از این روش، قادر به بهبود دقت در تعداد متنوعی از معماریهای شبکه های همگشتی موجود شده است.
در سال ۲۰۱۵ ژیگدی مدلی به نام GoogLeNet را ارائه داد که ساختار بسیار عمیقی داشت و دارای ۲۲ لایه بود و هر لایه شامل ترکیبی از لایه های همگشتی، پولینگ، سافت مکس و الحاقی بودند و توانست در رقابت ILSVRC2014 مقام اول را کسب کند.
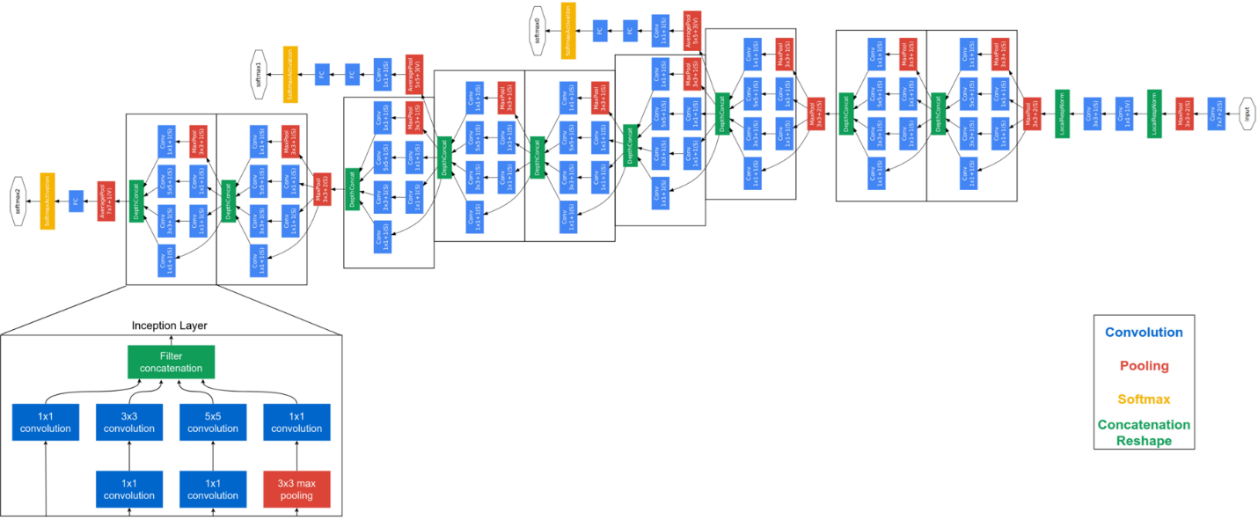
معماری شبکه گوگل نت
یک ایده شهودی این است که کارایی شبکههای همگشتی را با افزایش اندازه آنها که شامل افزایش عمق (تعداد سطوح) و عرض (تعداد واحدها در هر سطح) افزایش دهیم. معماری گوگل-نت از ۲۲ لایه استفاده کرده و با این کار نشان داد که افزایش اندازه برای دقت تشخیص تصویر سودمند است. اما یک مشکل عمده این معماری ها ثابت ماندن کارایی در حد مشخصی بود، به عبارتی دقت شبکه افزایش پیدا نمی کرد.
معماری رزنت، در سال ۲۰۱۵ معرفی شد و توانست عملگرد چشمگیری را به نمایش بگذارد. این معماری با عمق ۱۵۲ لایه، عمیق ترین معماری موجود می باشد و نسخههای مختلفی از این معماری ایجاد شده است. در این معماری به جای آنکه نگاشت دلخواه توسط چند لایه پشت سرهم بدست آید توسط یک چارچوب یادگیری مبتنی بر باقیمانده صورت می گیرد. در شکل زیر این چارچوب نمایش داده شده است.
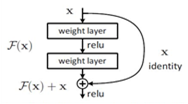
چارچوب مبتنی بر باقیمانده
مطرح ترین معماری های شبکه های عصبی همگشتی
سال: ۲۰۱۲
معماری: ۵ لایه همگشتی + ۳ لایه اتصال کامل
دستاورد: معماری مهمی که باعث علاقه بسیاری از محققان در زمینه بینایی کامپیوتر شد.
سال: ۲۰۱۳
معماری: ۵ لایه همگشتی + ۳ لایه اتصال کامل
دستاورد: باعث شد تا اتفاقاتی که در داخل شبکه رخ می دهد قابل دیدن باشند.
سال: ۲۰۱۴
معماری: ۵ لایه همگشتی + ۳ لایه اتصال کامل
دستاورد: با ارائه لایه پولینگ فضایی هرمی محدودیت اندازه تصاویر را از میان برداشت.
سال: ۲۰۱۴
معماری: ۱۵-۱۳ لایه همگشتی + ۳ لایه اتصال کامل
دستاورد: ارزیابی کاملی از شبکه با عمق افزایشی
سال: ۲۰۱۴
معماری: ۲۱ لایه همگشتی + ۱ لایه اتصال کامل
دستاورد: افزایش عمق و عرض شبکه بدون افزایش نیازمندی های محاسباتی
سال: ۲۰۱۵
معماری: ۱۵۲ لایه همگشتی +۱ لایه اتصال کامل
دستاورد: افزایش عمق شبکه و ارائه روشی جهت جلوگیری از اشباع شدگی گرادیانت
شبکه های عصبی مبتنی بر ناحیه لایه های همگشتی را به عنوان یک استخراج گر ویژگی مورد استفاده قرار داده و هیچ تغییری در شبکه اعمال نمیکند. اما برخلاف آن شبکه های همگشتی کامل روشی برای بازطراحی لایه های همگشتی به صورت شبکههای تمام همگشتی ارائه می کند که قادر به تولید خروجیهایی با اندازه متناسب به صورت بهینه است. اگرچه شبکههای همگشتی کامل عمدتا برای بخش بندی معنایی ارائه شده است اما این تکنیک را میتوان در کاربردهای دیگر نظیر دسته بندی تصاویر، تشخیص لبه و… نیز مورد استفاده قرار داد.
بخش بندی بر اساس تشخیص
این روش تصاویر را بر اساس پنجرههای کاندید خروجی حاصله از مرحله تشخیص شی قطعه بندی میکند. آر.سی.ان.ان ابتدا پیشنهادهایی برای هر ناحیه را برای تشخیص شی تولید کرده و سپس به قطعه بندی هر ناحیه و تخصیص پیکسل ها به هر کلاس می پردازد. یک مشکل بخش بندی بر اساس تشخیص، هزینه اضافی زیاد بابت تشخیص اشیاء است. دای و همکاران بدون استخراج نواحی از تصاویر خام، روشی تحت عنوان ویژگی های پوششی همگشتی را به منظور استخراج پیشنهادها به صورت مستقیم از نگاشت ویژگی ها طراحی کرد و از آنجایی که نگاشت ویژگی های همگشتی تنها یکبار نیازمند محاسبه شدن هستند، روش آنها بهینه و کارآمد است؛ هرچند که خطاهای ایجاد شده توسط پیشنهادها در فاز تشخیص شی معمولا دردسرساز می شود.
بخش بندی بر اساس تبدیل لایه های تمام متصل به لایه های کانولوشنی
دراین روش که استراتژی محبوب و پایهای برای انجام بخش بندی معنایی شده است، با جایگزینی لایههای اتصال کامل با لایههای همگشتی بیشتر، به قطعهبندی معنایی پرداخته میشود. لانگ در سال ۲۰۱۵ معماری نوینی را تعریف کرد که در آن اطلاعات معنایی از یک لایه جامع عمیق به همراه اطلاعات ظاهری از یک لایه کم عمق مناسب برای تولید قطعههای دقیق و با جزییات استفاده کرد. چن در سال ۲۰۱۴ با ارائه روشی مشابه شبکه دیپ لب را معرفی نمود و علاوه بر موارد فوق از چارچوب های تصادفی شرطی برای بازیابی دقیق مرزها استفاده کرد. لین در سال ۲۰۱۶ شبکههای عصبی همگشتی کامل و چارچوب های تصادفی شرطی را مشترکا در معماری خود استفاده کرد.