جهت کسب اطلاع در مورد رودمپ عمومی هوش مصنوعی روی لینک رو به رو کلیک کنید.
استخراج و انتخاب ویژگی
یکی از کارهای اولیه قبل از ساختن مدل یادگیری ماشین(ML)، شناسایی یا اصلاح داده های خارج از محدوده، داده های اشتباهی که توسط سنسورها ثبت شده، احتمال های غیر ممکن یا خطاهای اندازه گیری شده است. هنگامی که دادهها تمیز شدند، استخراج و انتخاب ویژگی، مراحل مهم بعدی در ساخت یک مدل ML هستند. در این نوشته، به توضیح استخراج ویژگی و انتخاب ویژگی پرداخته شده است.
استخراج ویژگی
استخراج ویژگی به فرآیند تبدیل دادههای خام به ویژگیهای عددی اشاره دارد که میتوان با حفظ اطلاعات در مجموعه دادههای اصلی، پردازش کرد. نتایج بهتری نسبت به استفاده از یادگیری ماشینی به طور مستقیم بر روی داده های خام به همراه دارد.
انواع روش های استخراج ویژگی
استخراج ویژگی را می توان به صورت دستی یا خودکار انجام داد:
۱. دستی
استخراج دستی ویژگی مستلزم شناسایی و توصیف ویژگیهایی است که برای یک مشکل خاص مرتبط هستند و روشی برای استخراج آن ویژگیها پیادهسازی میشود. در بسیاری از موقعیت ها، داشتن درک خوب از پس زمینه یا دامنه می تواند به تصمیم گیری آگاهانه در مورد اینکه کدام ویژگی می تواند مفید باشد کمک کند. در طول چندین دهه تحقیق، مهندسان و دانشمندان روشهای استخراج ویژگی را برای تصاویر، سیگنالها و متن توسعه دادهاند.
۲. خودکار
استخراج خودکار ویژگی ها از الگوریتم های تخصصی یا شبکه های عمیق برای استخراج خودکار ویژگی ها از سیگنال ها یا تصاویر بدون نیاز به دخالت انسان استفاده می کند. این تکنیک زمانی می تواند بسیار مفید باشد که بخواهید به سرعت از داده های خام به توسعه الگوریتم های یادگیری ماشینی بروید. پراکندگی موجک نمونه ای از استخراج خودکار ویژگی ها است.
با صعود یادگیری عمیق، استخراج ویژگی تا حد زیادی با اولین لایه های شبکه های عمیق جایگزین شده است. اما بیشتر برای داده های تصویر. برای کاربردهای سیگنال و سری زمانی، استخراج ویژگی اولین چالشی است که قبل از ساختن مدلهای پیشبینی مؤثر، به تخصص قابل توجهی نیاز دارد.
انتخاب ویژگی
اهمیت مرحله انتخاب ویژگی در طراحی مدلهای یادگیری
تحقیقات انجام شده در زمینه تاثیر انتخاب ویژگیهای مناسب در عملکرد روشهای یادگیری ماشین، نشان داده است که انتخاب مجموعه مناسب از ویژگیها در هنگام طراحی مدلهای یادگیری ماشین، عملکرد، دقت و کارایی روشهای یادگیری نظارت شده و نشده را بهبود میبخشد. همچنین، وقتی که ابعاد فضای ویژگی دادهها بسیار زیاد است استفاده از مجموعه ویژگیهای مناسب، هزینههای محاسباتی لازم برای آموزش بهینه سیستم را به شدت کاهش میدهد. محاسبه درجه اهمیت ویژگیها و استفاده از آنها در مرحله انتخاب ویژگی، گام مهمی در جهت تفسیرپذیری مدلهای یادگیری ماشین خواهد بود.
روشهای انتخاب ویژگی
روشهای انتخاب ویژگی به دو دسته کلی ارزیابی تکی و ارزیابی زیرمجموعهها تقسیم میشوند. ارزیابی تکی همچنین با عنوان رتبهبندی ویژگیها شناخته شده و ویژگیهای تکی را با تخصیص دادن وزن به آنها مطابق درجه ارتباطشان ارزیابی میکند. از سوی دیگر، ارزیابی زیرمجموعهها یک زیرمجموعه از ویژگیهای کاندید را بر اساس یک استراتژی جستوجوی خاص فراهم میکند. هر زیرمجموعه کاندید با استفاده از یک سنجه ارزیابی مشخص ارزیابی و با بهترینهای پیشین با توجه به این سنجه مقایسه میشود. در حالیکه ارزیابی فردی از حذف ویژگیهای دارای افزونگی به دلیل آنکه احتمال دارد ویژگیهای دارای افزونگی رتبهبندی مشابهی داشته باشند ناتوان است، رویکرد ارزیابی زیرمجموعهها میتواند افزونگی ویژگیها را با ارتباط ویژگیها مدیریت کند. اگرچه روشهای ارائه شده در این چارچوب دارای مشکلات اجتنابناپذیری هستند که به دلیل جستوجو در سراسر زیر مجموعههای ویژگی مورد نیاز در مرحله ساخت زیرمجموعه به وقوع میپیوندد و بنابراین هر دو روش انتخاب ویژگی بیان شده نیازمند مطالعات بیشتری هستند. در کنار این دستهبندی، سه رویکرد کلی انتخاب ویژگی با توجه به ارتباط بین الگوریتمهای انتخاب ویژگی و روش یادگیری استقرایی برای استنتاج یک مدل مورد استفاده قرار میگیرند. این موارد در ادامه بیان شدهاند.
روش های انتخاب ویژگی نظارت شده و نظارت نشده
بسته به نوع داده، انتخاب ویژگی را می توان به صورت نظارت شده، نیمه نظارت شده و بدون نظارت طبقه بندی کرد. اگر همه نمونه های داده در مجموعه داده دارای برچسب شناخته شده باشند، فرآیند انتخاب ویژگی “نظارت شده” نامیده می شود. اگر برخی از نمونههای داده دارای برچسب شناخته شده باشند و بقیه نداشته باشند، با مسئله انتخاب ویژگی «نیمه نظارت شده» روبرو هستیم. اگر هیچ یک از نمونه های داده دارای برچسب نباشد، انتخاب ویژگی انجام شده «نظارت نشده» نامیده می شود.
برای انتخاب بهترین ویژگیها برای یک مدل یادگیری نظارت شده، روش های انتخاب ویژگی نظارت شده ارائه شدهاند. هدف این دسته از الگوریتمها، انتخاب بهترین زیر مجموعه از ویژگیها برای تضمین عملکرد بهینه یک مدل نظارت شده به عنوان نمونه، مسائل دسته بندی و رگرسیون است. این الگوریتمها برای انتخاب بهترین ویژگیها، از داده های برچسب زده استفاده میکنند. با این حال، در شرایطی که دادههای برچسب زده در دسترس نیستند، روشهایی به نام روش های انتخاب ویژگی نظارت نشده پیادهسازی شدهاند که ویژگیها را براساس معیارهای مختلفی نظیر واریانس، آنتروپی، قابلیت ویژگیها در حفظ اطلاعات مرتبط با مشابهتهای محلی و سایر موارد امتیازبندی میکنند.
ویژگیهای مرتبطی که از طریق فرایندهای مکاشفهای نظارت نشده شناسایی شدهاند، میتوانند در مدلهای یادگیری نظارت شده نیز مورد استفاده قرار بگیرند. چنین کاربردهایی از ویژگیهای شناسایی شده، به سیستم یادگیری نظارت شده اجازه میدهد تا علاوه بر شناسایی میزان «همبستگی» ویژگیها با برچسب طبقه بندی دادهها، الگوهای دیگری نیز در دادههای یادگیری شناسایی کنند. از دیدگاه طبقهبندی، روش های انتخاب ویژگی را میتوان در چهار دسته زیر طبقهبندی کرد:
۱. روشهای فیلتر
فیلترها بر ویژگیهای کلی مجموعه داده آموزش تکیه دارند و فرآیند انتخاب ویژگی را به عنوان یک گام پیش پردازش با استقلال از الگوریتم استقرایی انجام میدهند. مزیت این مدلها هزینه محاسباتی پایین و توانایی تعمیم خوب آنها محسوب میشود. از روش های فیلتر، روش انتخاب ویژگی امتیاز فیشر و امتیاز کای 2 است.
۲. روشهای بستهبند
بستهبندها شامل یک الگوریتم یادگیری به عنوان جعبه سیاه هستند و از کارایی پیشبینی آن برای ارزیابی مفید بودن زیرمجموعهای از متغیرها استفاده میکنند. به عبارت دیگر، الگوریتم انتخاب ویژگی از روش یادگیری به عنوان یک زیرمجموعه با بار محاسباتی استفاده میکند که از فراخوانی الگوریتم برای ارزیابی هر زیرمجموعه از ویژگیها نشات میگیرد. با این حال، این تعامل با دستهبند منجر به نتایج کارایی بهتری نسبت به فیلترها میشود. از جمله روش های بسته بند می توان به تجزیه و تحلیل مولفه های همسایگی و انتخاب ویژگی مستقیم اشاره نمود.
۳. روشهای تعبیه شده
روشهای توکار یا تعبیه شده انتخاب ویژگی را در فرآیند آموزش انجام میدهند و معمولا برای ماشینهای یادگیری خاصی مورد استفاده قرار میگیرند. در این روشها، جستوجو برای یک زیرمجموعه بهینه از ویژگیها در مرحله ساخت دستهبند انجام میشود و میتوان آن را به عنوان جستوجویی در فضای ترکیبی از زیر مجموعهها و فرضیهها دید. این روشها قادر به ثبت وابستگیها با هزینههای محاسباتی پایینتر نسبت به بستهبندها هستند. رگرسیون لجستیکی چند جملهای اسپارس و رگرسیون تعیین خودکار مرتبط بودن جزء روش توکار هستند.
۴. روشهای ترکیبی
روشهای انتخاب ویژگی ترکیبی، با ترکیب روش های ذکر شده قبل، به انتخاب ویژگی می پردازد. گزینه دیگر برای انتخاب بهترین ویژگیها، ترکیب روشهای فیلتر و بستهبند است. در چنین روشهایی از یک فرآیند دو مرحلهای برای ترکیب دو روش فیلتر و بستهبند استفاده میشود. در مرحله اول، ویژگیها بر اساس مشخصههای آماری فیلتر میشوند. در مرحله بعد، با استفاده از یک روش انتخاب ویژگی بستهبند، بهترین ویژگیها برای آموزش یک مدل یادگیری انتخاب میشوند.
در جدول زیر خلاصهای از سه روش انتخاب ویژگی معرفی شده در بالا آمده و برجستهترین مزایا و معایب آنها را بیان شده است. با در نظر گرفتن این که چندین الگوریتم برای هر یک از رویکردهای پیشتر بیان شده وجود دارد باید گفت تعداد زیادی روش انتخاب ویژگی وجود دارد.
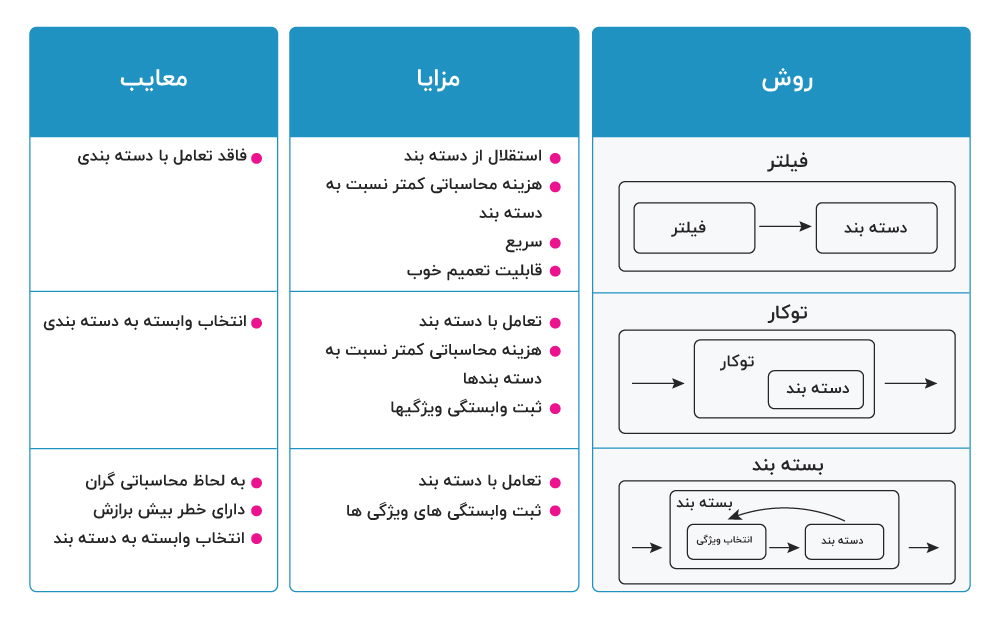
معرفی روش های انتخاب ویژگی
در این بخش، روشهای انتخاب ویژگی نظارت شده مبتنی بر همبستگی و تحلیل مؤلفههای همسایگی و همچنین از روش انتخاب ویژگی نظارت نشده واریانس، میانگین قدر مطلق تفاضلها، نسبت پراکندگی، چند خوشهای و روش امتیاز لاپلاس مورد بحث و بررسی قرار میگیرند.
روش های انتخاب ویژگی نظارت شده
۱. روش انتخاب ویژگی مبتنی بر همبستگی
در روش انتخاب ویژگی مبتنی بر همبستگی در مورد اقدامات مورد استفاده برای یافتن خوبی یک ویژگی برای طبقه بندی بحث می شود. این روش یک ویژگی را در صورتی خوب می داند که با ویژگی هدف، بیشتر مرتبط باشد و با هیچ ویژگی دیگر همبستگی نداشته باشد.
۲. تجزیه و تحلیل مولفه های همسایگی
تجزیه و تحلیل مولفه های همسایگی یا NCA یک الگوریتم یادگیری ماشینی برای یادگیری استاندارد است. تجزیه و تحلیل مولفه های همسایگی یک تبدیل خطی را به روش نظارت شده می آموزد تا دقت طبقه بندی قاعده های نزدیکترین همسایگان تصادفی را در فضای تبدیل شده بهبود بخشد.
روشهای انتخاب ویژگی نظارت نشده
۱. روش انتخاب ویژگی واریانس
روش «واریانس»، یکی از روشهای فیلتر نظارت نشده برای انتخاب ویژگی است. این روش، یکی از بهترین و موثرترین روشها برای انتخاب ویژگیهای مرتبطی است که معمولا امتیاز واریانس بالاتری دارند. روش واریانس به راحتی قادر خواهد بود تا ویژگیهای یکسان در نمونهها را حذف کند.
۲. روش انتخاب ویژگی میانگین قدر مطلق تفاضلها
در این روش، «میانگین قدر مطلق تفاضلها » برای ویژگیهای موجود در مجموعه داده، با استفاده «مقدار میانگین» ویژگیها محاسبه میشوند. ویژگیهایی که میانگین قدر مطلق تفاضل بالاتری داشته باشند، «قدرت متمایز کنندگی» بالاتری خواهند داشت؛ در نتیجه، ویژگیهای مرتبطتری هستند.
۳. روش انتخاب ویژگی نسبت پراکندگی
روش «نسبت پراکندگی»، از طریق محاسبه میانگین ریاضی، تقسیم بر، «میانگین هندسی » هر ویژگی، درجه اهمیت یا مرتبط بودن یک ویژگی را مشخص میکند. نسبت پراکندگی بالاتر برای یک ویژگی، به معنای مرتبطتر بودن آن ویژگی نسبت به دیگر ویژگیهای موجود در مجموعه داده است.
۴. روش انتخاب ویژگی امتیاز لاپلاسین
روش امتیاز لاپلاسین، بر پایه این مشاهده بنا نهاده شده است که دادههای یک کلاس یکسان، معمولا در همسایگی یکدیگر در فضای ویژگی قرار دارند؛ در نتیجه اهمیت یا مرتبط بودن یک ویژگی را میتوان از طریق محاسبه قدرت این ویژگی در حفظ اطلاعات «محلیت» نمونهها سنجید.
۵. روش انتخاب ویژگی چند خوشهای
در روش انتخاب ویژگی چند خوشهای، یک تحلیل طیفی با هدف اندازهگیری همبستگی میان ویژگیهای مختلف انجام میشود. بهترین «بردارهای ویژه» تولید شده از ماتریس لاپلاسین، برای خوشهبندی دادهها و محاسبه امتیاز برای هر کدام از ویژگیها مورد استفاده قرار میگیرند. ویژگی مهم این روش، انتخاب بهترین ویژگیها برای حفظ ساختار چند خوشه ای دادهها در یادگیری نظارت نشده است.
بسیاری از پژوهشگران توافق دارند که بهترین روش به صورت مطلق برای انتخاب ویژگی وجود ندارد و تلاش برای یافتن روشی است که برای هر مسئله به طور مشخص بهترین عملکرد را داشته باشد. روشهای گوناگونی برای مواجهه با مجموعه دادههای کلان مقیاس وجود دارد که اهمیت انتخاب ویژگی در آنها واقعیتی غیر قابل انکار است، زیرا منجر به کمینه کردن زمان آموزش و حافظه تخصیص داده شده با حفظ صحت نتایج میشود. با این حال، به یاد داشتن این امر حائز اهمیت است که بیشتر روشهای انتخاب ویژگی از کارایی مدل یاد گرفته شده به عنوان بخشی از فرآیند انتخاب استفاده میکنند. در حقیقت، از سه دسته بیان شده در بالا یعنی فیلترها، بستهبندها و روشهای توکار، تنها فیلترهای مستقل از الگوریتم هستند. این خصوصیت موجب میشود که فیلترها به لحاظ محاسباتی ساده و سریع و همچنین قادر به مدیریت مجموعه دادههای کلان مقیاس باشند. اغلب فیلترها تک متغیره هستند، هر ویژگی را مستقل از سایر ویژگیها در نظر میگیرند، و این امر میتواند منجر به غلبه بر روشهای چند متغیرهای شود که نیازمند منابع محاسباتی بیشتر هستند.