جهت کسب اطلاع در مورد رودمپ عمومی هوش مصنوعی روی لینک رو به رو کلیک کنید.
شبکه های مولد تخاصمی (GANs)
فهرست محتوا:
- شبکه مولد تخاصمی چیست؟
- معماری شبکه مولد تخاصمی
- آموزش شبکه های مولد تخاصمی
- پیش پردازش داده
- تعیین معماری مولد
- تعیین معماری متمایزگر
- آموزش مولد و متمایزگر
- ارزیابی GAN
- تنظیم GAN
- جمع بندی
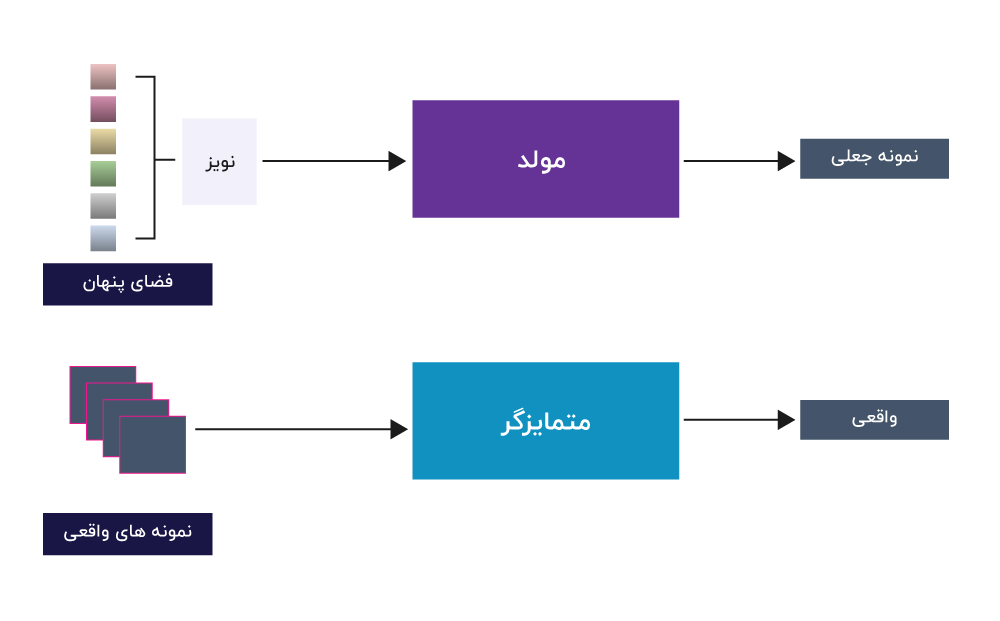
شبکه مولد تخاصمی چیست؟
شبکه های مولد تخاصمی (GANs)، پیشرفت قابل توجهی در یادگیری ماشین به شمار می روند که توجه بسیاری از پژوهشگران و کارشناسان صنعت را به خود جلب نموده اند. GAN ها از روش های قدرتمند یادگیری عمیق همچون شبکه های عصبی کانولوشن به منظور یادگیری پترن ها و رگولاریتی های یک مجموعه داده مورد نظر استفاده میکنند. همچنین از این دانش برای ایجاد نمونه های جدید که شباهت زیادی به نمونه های واقعی دارند استفاده می نمایند. مدل مولد(Generator)، ورودی تصادفی دریافت نموده و نمونه های جدیدی ایجاد می نماید که مشابه دیتاست اصلی هستند. در حالیکه مدل متمایزگر(Discriminator)، ارزیابی واقعی یا جعلی بودن را به عهده دارد. مولد سعی دارد تا نمونه های واقعی تری تولید نماید و از این طریق، متمایزگر را به اشتباه بندازد. از طرفی، متمایزگر سعی می کند تا میان نمونه های واقعی و جعلی تمایز قائل شود. این فرآیند تا زمانی ادامه دارد که مولد(Generator) بتواند نمونه های چنان واقعی تولید نماید که از نمونه های واقعی قابل تفکیک نباشد.
یکی از جالب ترین ویژگی های شبکه های مولد تخاصمی، توانایی آنها در تولید تصاویر و ویدئوهای فتو رئالیستیک است. این شبکه ها نتایج موفقی در تبدیل تصویر به تصویر برای مثال تبدیل روز به شب یا زمستان به تابستان داشته اند. همچنین شبکه های مولد تخاصمی (GANs) برای ساخت تصاویر فتورئالیستیک از اشیا، مناظر و افراد که به سختی از تصاویر واقعی تشخیص داده میشوند، مورد استفاده قرار می گیرند. سایر کاربردهای قابل توجه این شبکه ها در حوزه هایی همچون تبلیغات، سرگرمی و بازی می باشد که به منظور تولید محتوای باکیفیت اهمیت فراوانی دارد.
در این نوشته، به بررسی کامل معماری و آموزش شبکه های مولد تخاصمی میپردازیم تا محدودیت ها و قابلیت های آنان به طور کامل درک گردد.
معماری شبکه مولد تخاصمی
شبکه های مولد تخاصمی (Generative Adversarial Networks) که به طور مخفف GANs نیز گفته می شوند، نوعی مدل مولد مبتنی بر یادگیری عمیق هستند. این شبکه ها برای نخستین بار در سال ۲۰۱۴ در مقاله ای توسط ایان گودفلو (Ian Goodfellow) و تیمش معرفی گردید.
GANها نوعی شبکه عصبی هستند که برای یادگیری بدون نظارت (Unsupervised Learning) مورد استفاده قرار می گیرند به این معنی که قابلیت ایجاد داده جدید را دارند بدون آنکه به طور مشخص به آنها گفته شود که چه چیزی را تولید نمایند. GAN ها را میتوان به دو بخش تقسیم کرد: مدل مولد و مدل متمایزگر.
مدل متمایزگر بر روی داده های واقعی آموزش میبیند و یاد میگیرد که داده های واقعی چگونه هستند. مدل متمایزگر بسته به اینکه داده واقعی یا جعلی باشد دارای دو مقدار خروجی ۰ و ۱ می باشد.
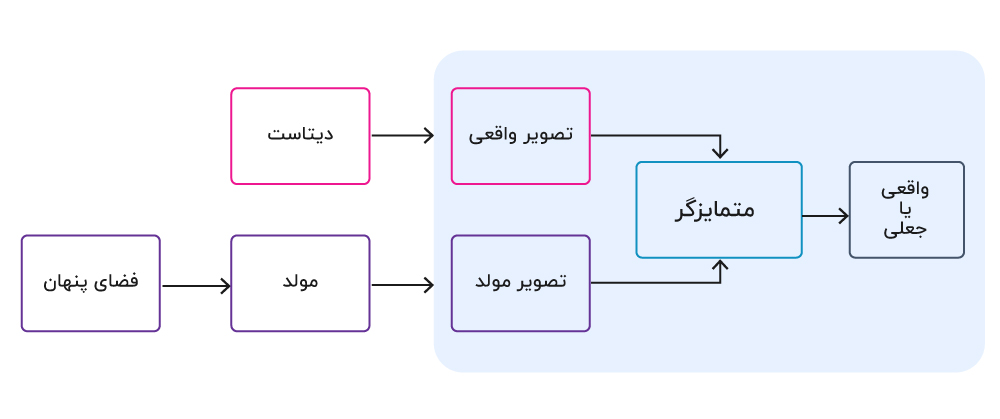
از طرفی دیگر، مدل مولد یک بردار نویز تصادفی را به عنوان ورودی دریافت کرده و داده های جدیدی را بر اساس این ورودی ها تولید می نماید. هدف مولد، ایجاد داده های جعلی بسیار نزدیک به داده های واقعی است که متمایزگر را فریب دهد تا آنها را به اشتباه به عنوان داده واقعی شناسایی نماید. مولد تا جایی خروجی خود را بهبود میبخشد که متمایزگر، توانایی شناسایی داده واقعی از جعلی را نداشته باشد.
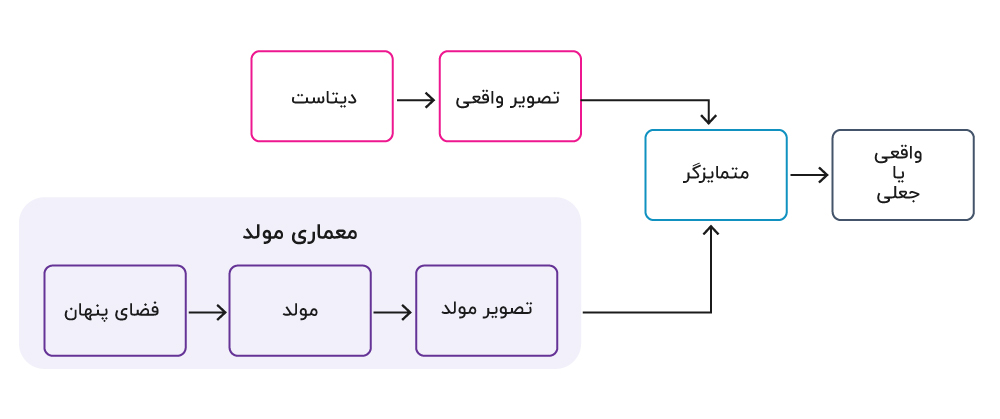
آموزش شبکه های مولد تخاصمی
دو بخش از GAN – مولد و متمایزگر – به صورت همزمان در یک بازی minmax آموزش داده می شوند که هدف مولد ایجاد نمونه های واقعی جهت فریب متمایزگر است. در حالیکه متمایزگر تلاش میکند تا داده های واقعی و جعلی را به درستی دسته بندی نماید. در ادامه برخی از گام های آموزش GANها با مثال شرح داده می شود:
پیش پردازش داده
پیش پردازش داده ها در یادگیری ماشین بسیار مهم است، زیرا شامل تبدیل داده های خام به قالبی است که می تواند به طور موثر توسط الگوریتم های یادگیری ماشین مورد استفاده و تجزیه و تحلیل قرار گیرد. در زمینه GAN ها، پیش پردازش مناسب داده تضمین می کند که مدل های مولد و متمایزگر، داده های ورودی را با فرمت صحیح و پاکسازی شده برای آموزش دریافت می کنند.
پیش پردازش داده شامل چندین مرحله مهم از جمله تمیز کردن، نرمال سازی، تبدیل و تقویت است. پاکسازی داده ها(Data Cleaning) شامل حذف داده های نامربوط یا دارای نویز از مجموعه داده ها است، در حالی که نرمال سازی داده ها(Data Normalization) تضمین می کند که داده های ورودی دارای محدوده های مشابهی از مقادیر هستند و نسبت به هیچ ویژگی خاصی تعصب ندارند. تبدیل داده(Data Transformation) شامل تبدیل داده های ورودی به قالبی است که الگوریتم های یادگیری ماشینی به راحتی می توانند آن را پردازش کنند. تقویت داده ها(Data Augmentation) به افزایش تنوع مجموعه آموزشی و بهبود عملکرد مدل با ایجاد نمونه های آموزشی جدید از طریق تبدیل هایی مانند برش و چرخش تصاویر کمک می کند.
در مورد دیتاست های تصویری، تمیز کردن داده ها ممکن است شامل حذف تصاویر تار یا خراب باشد، در حالی که تبدیل داده ها ممکن است شامل تغییر اندازه یا تبدیل تصاویر به مقیاس خاکستری یا فرمت فایل خاص باشد. اهمیت پیش پردازش داده ها را نمی توان نادیده گرفت، چراکه می تواند به طور قابل توجهی بر عملکرد و دقت مدل های یادگیری ماشین موثر باشد.
تعیین معماری مولد
مولد در یک شبکه مولد تخاصمی (GAN)، ورودی را از یک بردار نویز تصادفی می گیرد و خروجی مشابه داده های واقعی را برای ایجاد نمونه های داده جدید تولید می کند که توزیع داده های واقعی را تقریب می کند. بنابراین، برای توسعه مدل GAN موفق، ضروری است که معماری مولد را به روشی مناسب تعریف کنیم که شامل چندین مرحله است:
لایه ورودی: مولد یک بردار نویز تصادفی را به عنوان ورودی میگیرد که معمولا از یک توزیع یکنواخت یا گاوسی بدست می آید.
لایه های مخفی: مولد از شماری از لایه های پنهان برای تبدیل بردار نویز به یک خروجی که مشابه داده واقعی باشد استفاده مینماید. معماری های مختلف شبکه های عصبی همچون لایه های کاملا متصل، لایه های کانولوشن یا لایه های بازگشتی به منظور پیاده سازی این لایه های پنهان مورد استفاده قرار می گیرند.
لایه خروجی: لایه نهایی مولد، خروجی را تولید میکند. تعداد نورون ها در این لایه بایستی با متناسب با ابعاد داده های واقعی باشند.
توابع فعالسازی: تابع فعالسازی مورد استفاده در لایه خروجی بستگی به دیتاتایپ تولیدشده دارد. برای مثال، تابع فعالسازی سیگموید معمولا برای تولید مقادیر خروجی بین 0 و 1 برای داده های تصویری استفاده می شود.
تابع هزینه: تابع هزینه cross-entropy باینری معمولا به منظور سنجش تفاوت میان خروجی تولید شده و داده واقعی در طی فرآیند آموزش استفاده می شود.
بهینه سازی: مولد توسط یک بهینه ساز همچون گرادیان کاهشی تصادفی (SGD) یا آدام (Adam) آموزش داده می شود.
هایپرپارامترها: برای آموزش مولد لازم است که چندین هایپر پارامتر همچون نرخ یادگیری، اندازه دسته(batch)، تعداد دوره ها(epochs) و اندازه لایه های پنهان تعریف گردد.
تعیین معماری متمایزگر
در شبکه مولد متخاصم، متمایزگر یک شبکه عصبی است که مسئول دسته بندی داده های تولید شده توسط مولد می باشد.
به منظور تعریف معماری متمایزگر در GAN، ابتدا نیاز است تا ابعاد ورودی و خروجی متمایزگر مشخص شود. ابعاد ورودی، اندازه تصویر یا داده ای است که متمایزگر قصد دسته بندی آن را دارد. درحالیکه، ابعاد خروجی به طور معمول یک خروجی باینری است که بیان میکند ورودی واقعی یا جعلی است. پس از تعیین ابعاد ورودی و خروجی، میتوان طراحی معماری شبکه عصبی متمایزگر را شروع کرد. متمایزگر به طور معمول از لایه های شبکه عصبی کانولوشن (CNN) برای استخراج ویژگی ها از داده های ورودی استفاده میکند. سپس این ویژگی ها به یک لایه کامل متصل داده می شود که خروجی آن دسته بندی باینری واقعی یا جعلی است. تعداد لایه های CNN و اندازه فیلترهای مورد استفاده در این لایه ها، هایپرپارامترهایی هستند که امکان تنظیم شدن بر اساس اندازه و پیچیدگی داده های ورودی را دارند. به طور کلی، تعداد لایه های CNN میتواند از تعداد اندک تا هزاران لایه متغیر باشد و این بستگی به پیچیدگی دیتاست دارد.
علاوه بر این، لایه نرمال سازی batch را میتوان به منظور بهبود پایداری و عملکرد متمایزگر بین لایه های CNN اضافه نمود. لایه های Dropout را نیز میتوان به منظور پیشگیری از بیش برازش متمایزگر استفاده نمود. تابع هزینه متمایزگر در GAN به طور معمول cross-entropy باینری می باشد که اختلاف میان برچسب های خروجی واقعی و پیش بینی شده را اندازه گیری مینماید.
آموزش مولد و متمایزگر
در یک شبکه مولد تخاصمی (GAN)، آموزش متمایزگر شامل استفاده از داده های واقعی و جعلی برای آموزش طبقه بندی کننده باینری جهت تعیین تمایز میان این دو است. این مراحل شامل ایجاد یک دیتاست آموزشی، تولید دادههای جعلی، ترکیب دادههای واقعی و جعلی، آموزش متمایزگر با استفاده از پس انتشار(Backpropagation)، و بهروزرسانی مولد است. برعکس، آموزش مولد مستلزم بهینهسازی وزنهای آن برای تولید دادههای جعلی است که میتوانند متمایزگر را فریب دهند. این مراحل شامل تولید داده های جعلی، دادن آن به متمایزگر، محاسبه هزینه یا زیان مولد، پس انتشار هزینه برای به روز رسانی وزن های مولد و تکرار فرآیند است. در نهایت، آموزش هر دو بخش به طور همزمان شامل تولید بردارهای نویز تصادفی، ایجاد batch های ترکیبی از دادههای واقعی و جعلی، آموزش متمایزگر، تولید batch های جدید از دادههای جعلی، تنظیم برچسبهای «واقعی» برای دادههای جعلی و بهروزرسانی وزنهای مولد با استفاده از هزینه یا زیان مولد. این فرآیند آموزش خصمانه در طول زمان، تعداد بیشتری دادههای جعلی واقعیتر را تولید میکند و در نتیجه، تصاویر بسیار قانعکنندهای ایجاد میکند که تشخیص آنها از تصاویر اصلی و واقعی دشوار است.
فرآیند آموزش مولد و متمایزگر با هم در یک GAN اغلب به عنوان آموزش تخاصمی شناخته می شود زیرا این دو جزء در رقابت با هم کار می کنند. این فرآیند می تواند چالش برانگیز باشد، زیرا مولد و متمایزگر باید یاد بگیرند که با رفتار یکدیگر سازگار شوند تا نتایج با کیفیت بالاتری تولید کنند. با این حال، هنگامی که GAN ها به درستی انجام شوند، می توانند تصاویر بسیار مشابه با واقعی را تولید کنند که تشخیص آنها از تصاویر اصلی دشوار است.
ارزیابی GAN
ارزیابی عملکرد یک GAN در طول آموزش میتواند چالش برانگیز باشد زیرا هدف نهایی، تولید نمونه های واقعی است که بسیار شبیه توزیع داده های واقعی باشد. بنابراین، ارزیابی کیفیت نمونه های تولید شده ذهنی است و به حوزه خاص داده بستگی دارد.
یکی از روش های رایج ارزیابی GAN، بکارگیری ترکیبی از معیارهای کیفی و کمی است. ارزیابی کیفی شامل بررسی بصری و مقایسه نمونه های تولید شده با نمونه های واقعی است. به عنوان مثال، اگر GAN تصاویر تولید می کند، می توانیم تصاویر تولید شده را با نمونه ای از تصاویر واقعی از مجموعه آموزشی مقایسه کنیم تا ببینیم چقدر واقعی به نظر می رسند. اگر GAN متن تولید میکند، میتوانیم آن را با نمونهای از متن واقعی از مجموعه آموزشی مقایسه کنیم تا ببینیم چقدر منسجم و از نظر گرامری درست است.
ارزیابی کمی شامل استفاده از معیارها برای ارزیابی عددی کیفیت نمونه های تولید شده است. برخی از معیارهای کمی رایج برای GAN ها عبارتند از:
امتیاز ادراکی(Inception score): این امتیاز، تنوع و کیفیت نمونه های تولید شده را اندازه گیری می کند. واگرایی KL بین توزیع کلاس حاشیه ای نمونه های تولید شده و نمونه های واقعی را محاسبه می کند و همچنین اطمینان طبقه بندی کننده را در طبقه بندی نمونه های تولید شده اندازه گیری می کند.
فاصله فرشه (Frechet Inception Distance): این مورد، شباهت بین توزیع نمونه های واقعی و تولید شده در فضای ویژگی را اندازه گیری می کند. از فعالسازی های یک لایه میانی طبقهبندیکننده از پیش آموزشدیده برای محاسبه فاصله استفاده میکند.
صحت (Recall) و دقت (Precision): این دو معیارهایی از حوزه بازیابی اطلاعات هستند و می توانند برای اندازه گیری کیفیت متن یا تصاویر تولید شده استفاده شوند. دقت، بررسی میکند که چه تعداد از نمونههای تولید شده، مرتبط (یعنی مشابه نمونههای واقعی) هستند. در حالی که صحت، تعداد نمونههای مرتبط تولید شده را اندازهگیری میکند.
فاصله واسرشتاین (Wasserstein distance): این مورد، فاصله بین توزیع های واقعی و تولید شده را بر حسب چگالی احتمال آنها اندازه گیری می کند. معمولاً در Wasserstein GANs برای آموزش GAN استفاده می شود.
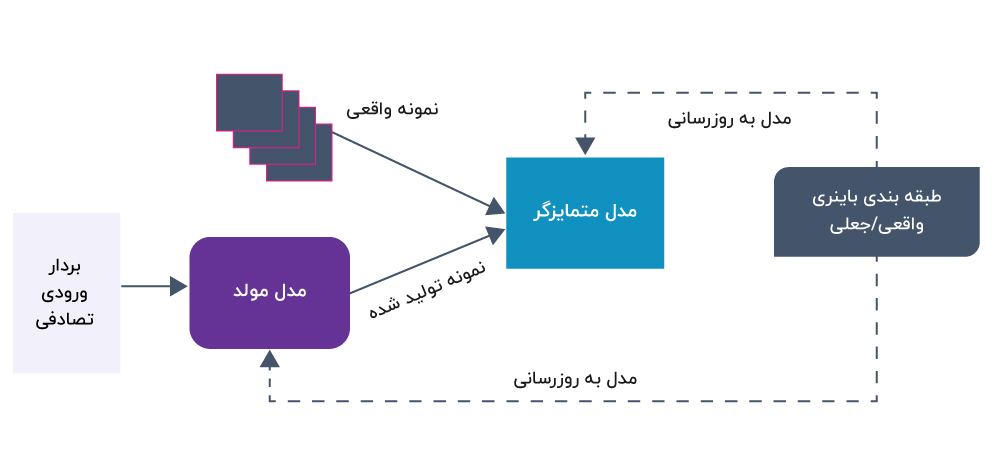
توجه به این نکته مهم است که ارزیابی GAN در طول آموزش یک فرآیند مستمر است. همانطور که GAN آموزش داده می شود، کیفیت نمونه های تولید شده ممکن است بهبود یابد، اما GAN ممکن است با مشکل mode collapse یا سایر چالش ها مواجه شود. بنابراین، نظارت بر GAN در طول آموزش برای اطمینان از یادگیری موثر و تولید خروجیهای با کیفیت بسیار مهم است. یکی از راههای نظارت بر GAN، بررسی توابع هزینه/زیان شبکههای مولد و متمایزگر است که میتواند اطلاعات ارزشمندی در مورد پیشرفت آموزش و شناسایی مشکلات بالقوه ارائه دهد. به عنوان مثال، اگر هزینه مولد به طور مداوم بیشتر از هزینه متمایزگر باشد، ممکن است نشان دهنده این باشد که مولد نمونه های واقعی تولید نمی کند.
تنظیم GAN
تنظیم شبکه مولد تخاصمی (Tuning the GAN) در طی آموزش به منظور دستیابی به نتایج بهینه دارای اهمیت است که شامل بهینه سازی پارامترهای مختلف موثر بر فرآیند آموزش و کیفیت داده های تولید شده می باشد.
در ادامه، چند هایپرپارامتر مهم که در طی فرآیند آموزش GAN تنظیم می شوند آورده شده است:
نرخ یادگیری: نرخ یادگیری مشخص می کند که مدل با چه سرعتی پارامترهای خود را در طی آموزش تنظیم میکند. این یک هایپرپارامتر مهم است که می تواند بر پایداری آموزش GAN موثر باشد. چنانچه نرخ یادگیری بسیار بالا باشد، شبکه مولد تخاصمی ممکن است ناپایدار شده و قابلیت همگرایی نداشته باشد. از طرفی دیگر، در صورتی که نرخ یادگیری بسیار پایین باشد، فرآیند آموزش ممکن است بسیار کند شده و مدت زمان بیشتری طول بکشد تا نمونه های باکیفیت تولید نماید.
اندازه دسته (Batch size): اندازه دسته، تعداد نمونه های آموزش مورد استفاده در یک تکرار(iteration) آموزش است که تعداد نمونه های تولید شده توسط مولد و تعداد نمونه های مورد استفاده توسط متمایزگر برای یادگیری را مشخص می کند. اندازه دسته بزرگ تر می تواند موجب افزایش سرعت فرآیند آموزش شود، اما همچنین ممکن است موجب بیش برازش شده و تنوع نمونه های تولید شده را کم کند. هرچه اندازه دسته کوچک تر باشد، موجب همگرایی بهتر GAN شده اما در عین حال ممکن است زمان آموزش را طولانی تر نماید.
تابع هزینه(Loss Function): انتخاب تابع هزینه در فرآیند آموزش GAN بسیار مهم است. مولد و متمایزگر دارای توابع هزینه متفاوت هستند که لازم است به دقت طراحی گردد تا فرایند آموزش را بهینه نماید. برای مثال، تابع هزینه مولد ممکن است از هزینه تخاصمی (adversarial loss) استفاده نماید که تشابه میان نمونه های واقعی و تولید شده را اندازه گیری می کند. برخلاف آن، تابع هزینه متمایزگر میتواند از cross-entropy باینری استفاده کرده که کیفیت ایجاد تمایز میان نمونه های واقعی و جعلی را اندازه گیری می کند.
معماری: معماری GAN شامل تعداد لایه ها، نورون ها و نوع توابع فعال سازی مورد استفاده در شبکه های مولد و متمایزگر است. بنابراین، انتخاب یک معماری مناسب که یک موازنه میان پیچیدگی شبکه مولد تخاصمی و پایداری آن برقرار نماید، اهمیت دارد. معماری های پیچیده، قابلیت تولید نمونه های متنوع تر و باکیفیت تر را دارند اما از طرفی، ممکن است موجب بیش برازش شوند که بر پایداری GAN تاثیر منفی دارد.
جمع بندی
شبکههای مولد تخاصمی (GAN) یک تکنیک یادگیری ماشینی فوقالعاده قدرتمند و هستند که حوزه تولید داده را بهطور اساسی متحول میکند. اگرچه معماری و فرآیند آموزش GAN ها پیچیده است، اما برای درک نحوه بهینه سازی عملکرد آنها برای کاربردهای خاص ضرورت دارد. با کنکاش در معماری و فرآیند آموزش GAN ها، اطلاعات ارزشمندی در مورد چگونگی کار این مدل ها و نحوه آموزش موثر آنها به دست آورده ایم. همچنین، نحوه کار بخش های مولد و متمایزگر به منظور تولید دادههای مشابه دادههای آموزشی واقعی را بررسی کردیم.
همانطور که GAN ها به پیشرفت خود ادامه می دهند، کاربردهای آنها بدون شک گسترش خواهند یافت و فرصت های هیجان انگیز جدیدی را برای تولید داده ها و زمینه های دیگر فراهم می کنند.