ساخت برنامههای مبتنی بر LLM
LangChain یک چارچوب برای ساخت برنامههای مبتنی بر LLM است که با ارائه موارد زیر به شما در ساخت برنامههای مبتنی بر LLM کمک میکند:
- رابط عمومی برای تعداد متنوعی از مدلهای پایه
- چارچوبی برای کمک به مدیریت Prompt های شما
- رابط مرکزی برای حافظه طولانی مدت (Memory)، دادههای خارجی (Indexes)، سایر LLMها (Chains) و عاملهای دیگر برای کارهایی که LLM قادر به انجام آن نیست (مانند محاسبات یا جستجو)
در ادامه آموزش کار با LangChain، یک پروژه متن باز (GitHub) را که توسط Harrison Chase ایجاد شده است با هم بررسی می کنیم.
با توجه به تنوع ویژگیهای LangChain، ممکن است در ابتدا درک اینکه دقیقا چه کاری انجام میدهد برای شما چالش برانگیز باشد. به همین دلیل، در این مقاله تحت عنوان آموزش کار با LangChain به شما شش ماژول اصلی LangChain را معرفی میکنیم تا بتوانید با قابلیتهای آن آشنا شوید.
پیش نیازها
برای این آموزش، شما باید بسته پایتون langchain را نصب کرده و همه کلیدهای API مربوطه را آماده استفاده داشته باشید.
نصب LangChain
قبل از نصب بسته langchain ، مطمئن شوید که نسخه پایتون ≥ 3.8.1 را دارید.
برای نصب بسته پایتون langchain ، میتوانید آن را با استفاده از دستور pip نصب کنید.
pip install langchain
در آموزش کار با LangChain، ما از نسخه 0.0.147 استفاده می کنیم. بعد از نصب و تنظیمات مورد نیاز، بسته پایتون langchain را ایمپورت کنید.
import langchain
کلیدهای API
برای ساخت برنامههای مبتنی بر LLM، برخی از سرویسهایی که میخواهید استفاده کنید به کلیدهای API نیاز دارند که نیاز به پرداخت هزینه دارند.
ارائه دهنده LLM (الزامی) – ابتدا باید کلید API برای ارائه دهنده LLM که میخواهید استفاده کنید را داشته باشید. در حال حاضر توسعه دهندگان باید بین مدلهای Proprietary یا Open-source، براساس مقایسه بین عملکرد و هزینه، انتخاب کنند.
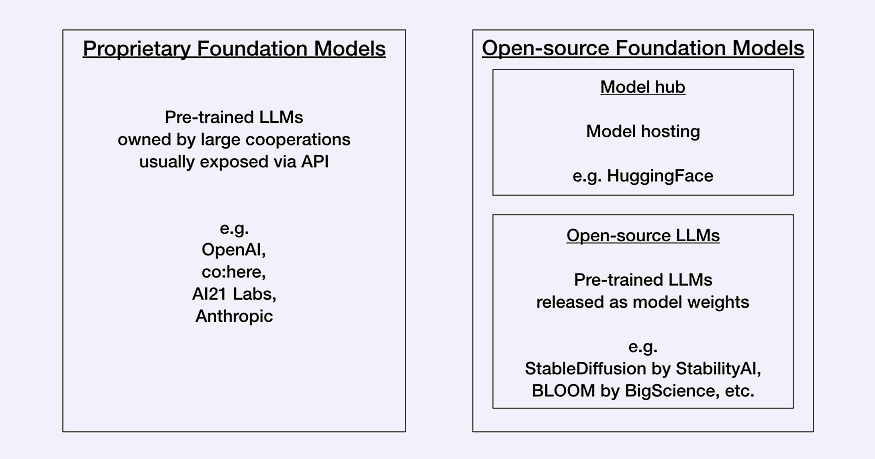
مدلهای مالکیتی(Proprietary)، مدلهای closed-source هستند که توسط شرکتهایی با تیمهای تخصصی بزرگ و بودجههای کلان هوش مصنوعی تولید شدهاند. آنها معمولاً بزرگتر از مدلهای اپن سورس هستند و به همین دلیل عملکرد بهتری دارند، همچنین API های گران قیمتی دارند. مثال هایی از ارائه دهندگان مدل مالکیتی عبارتند از:
بیشتر آموزشهای LangChain موجود از OpenAI استفاده میکنند، اما توجه داشته باشید که OpenAI API رایگان نیست، بلکه برای بدست آوردن کلید OpenAI API نیاز به حساب OpenAI دارید و سپس در بخش API keys گزینه “Create new secret key” را انتخاب کنید.
import os os.environ["OPENAI_API_KEY"] = ... # insert your API_TOKEN here
مدلهای اپن سورس معمولاً مدلهای کوچکتر با قابلیتهای کمتر از مدلهای مالکیتی هستند، اما نسبت به آنها هزینههای کمتری دارند. مثال هایی از مدلهای اپن سورس عبارتند از:
بسیاری از مدلهای اپن سورس در Hugging Face به عنوان یک community hub سازماندهی و میزبانی میشوند. برای بدست آوردن کلید Hugging Face API، نیاز به اکانت Hugging Face و ایجاد “New token” در بخش Access Tokens دارید.
import os os.environ["HUGGINGFACEHUB_API_TOKEN"] = ... # insert your API_TOKEN here
شما میتوانید از Hugging Face برای مدلهای LLM اپن سورس به صورت رایگان استفاده کنید، اما به مدلهای کوچکتر با عملکرد کمتر محدود خواهید شد.
دیتابیس برداری (اختیاری) – اگر می خواهید از یک پایگاه داده برداری خاص مانند Pinecone ،Weaviate یا Milvus استفاده کنید، باید با آنها ثبت نام کرده و کلید API را بدست آورید و قیمت های آنها را بررسی کنید. در این آموزش از Faiss استفاده می کنیم که نیازی به ثبت نام ندارد.
ابزارها (اختیاری) – بسته به ابزارهایی که میخواهید LLM با آنها تعامل داشته باشد مانند OpenWeatherMap یا SerpAPI، شاید نیاز باشد با آنها ثبت نام کرده و کلید API را بدست آورید و قیمت های آنها را بررسی کنید. در این آموزش، تنها از ابزارهایی که نیاز به کلید API ندارند، استفاده می کنیم.
با LangChain چه کاری می توان انجام داد؟
در نسخه فعلی LangChain (نسخه 0.0.147)، شش ماژول پوشش داده شده است. این شش ماژول اصلی است که LangChain آنها را پوشش میدهد عبارتند از:
۱. Models: این ماژول شامل کلاسهای مدل زبانی است و رابط عمومی برای متصل کردن به مدلهای زبانی و APIهای LLM و مدل های Embeddings را فراهم می کند.
۲. Prompts: این ماژول کلاسهایی برای مدیریت ورودی LLM، مانند قالب های Prompts، فراهم می کند و به کاربران کمک می کند تا به راحتی ورودیهای خود را برای تولید متن از مدلهای زبانی مدیریت و سفارشی کنند.
۳. Chains: این ماژول به کاربران اجازه می دهد تا LLM ها را با سایر مولفه ها مانند قالب های Prompts، داده های خارجی و ابزارهای دیگر ترکیب کنند تا مدل های زبانی پیچیده تری ایجاد کنند.
۴. Indexes: این ماژول شامل توابعی برای دسترسی به داده های خارجی مانند پایگاه داده ها یا منابع دیگر است که می تواند برای بهبود عملکرد مدل های زبانی استفاده شود.
۵. Memory: این ماژول کلاسهایی برای به یاد سپردن مکالمات قبلی فراهم می کند، که می تواند برای ایجاد مدل های زبانی با آگاهی بیشتر از متن مورد نظر استفاده شود.
۶. Agents: این ماژول کلاسهایی برای دسترسی به ابزارها، خدمات یا API های دیگری که می تواند همراه با مدل های زبانی LangChain استفاده شود، فراهم می کند.
در ادامه مقاله آموزش کار با LangChain، هر یک از این ماژول ها به تفصیل شرح داده خواهد شد. کدهای مثال در بخشهای بعدی از مستندات LangChain استفاده و به روزرسانی شدهاند.
Models: انتخاب از مدلهای زبانی و مدلهای Embeddings مختلف
در حال حاضر، مدلهای زبانی بسیار مختلفی ظاهر شدهاند. LangChain قابلیت یکپارچه سازی با مجموعه گستردهای از این مدلها را فراهم میکند و رابط ساده ای برای همه آنها ارائه میدهد.
LangChain بین سه نوع مدل که در ورودی و خروجی متفاوت هستند، تمایز قائل می شود:
- LLM ها یک رشته را به عنوان ورودی (Prompt) دریافت کرده و یک رشته (completion) را به عنوان خروجی تولید میکنند.
# Proprietary LLM from e.g. OpenAI # pip install openai from langchain.llms import OpenAI llm = OpenAI(model_name="text-davinci-003") # Alternatively, open-source LLM hosted on Hugging Face # pip install huggingface_hub from langchain import HuggingFaceHub llm = HuggingFaceHub(repo_id = "google/flan-t5-xl") # The LLM takes a prompt as an input and outputs a completion prompt = "Alice has a parrot. What animal is Alice's pet?" completion = llm(prompt)

- Chat Model ها شباهت زیادی به LLM ها دارند. آنها لیستی از پیامهای گفتگو را به عنوان ورودی دریافت کرده و یک پیام گفتگو را به عنوان خروجی تولید میکنند.
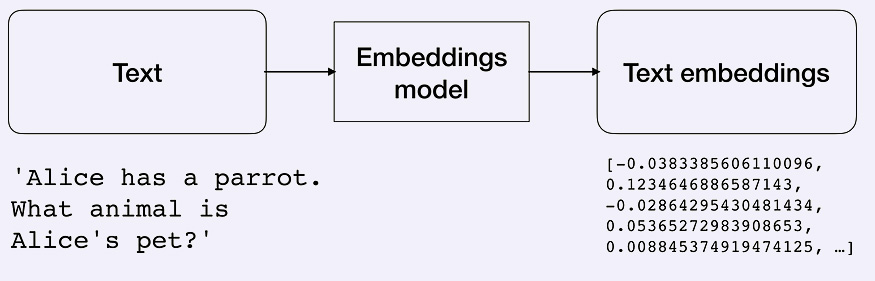
- Text embedding model ها، ورودی متنی را دریافت کرده و لیستی از اعداد اعشاری(embeddings) را بر میگردانند که نمایش عددی ورودی متنی است. Embedding ها به استخراج اطلاعات از متن کمک میکنند. سپس این اطلاعات میتوانند برای محاسبه شباهت بین متون (مانند خلاصه فیلمها) استفاده شوند.
# Proprietary text embedding model from e.g. OpenAI # pip install tiktoken from langchain.embeddings import OpenAIEmbeddings embeddings = OpenAIEmbeddings() # Alternatively, open-source text embedding model hosted on Hugging Face # pip install sentence_transformers from langchain.embeddings import HuggingFaceEmbeddings embeddings = HuggingFaceEmbeddings(model_name = "sentence-transformers/all-MiniLM-L6-v2") # The embeddings model takes a text as an input and outputs a list of floats text = "Alice has a parrot. What animal is Alice's pet?" text_embedding = embeddings.embed_query(text)
Prompts: مدیریت ورودی های LLMs
API های LLM ها عجیب هستند. اگرچه ورود Prompt ها به LLM ها با زبان طبیعی برای کاربران باید احساس شهودی داشته باشد، اما برای رسیدن به خروجی مطلوب از LLM ها نیاز به تنظیمات و تغییرات Prompt ها دارید. این فرآیند با نام Prompt Engineering شناخته میشود.
پس از داشتن یک Prompt خوب، ممکن است بخواهید از آن به عنوان یک الگو برای اهداف دیگر استفاده کنید. بدین منظور، LangChain با استفاده از مجموعه PromptTemplate به شما کمک میکند تا با استفاده از چندین مولفه، Prompt های خود را ساختاردهی کنید.
from langchain import PromptTemplate
template = "What is a good name for a company that makes {product}?"
prompt = PromptTemplate(
input_variables=["product"],
template=template,
)
prompt.format(product="colorful socks")Prompt فوق میتواند به عنوان یک تنظیم مسئله برای LLM مشاهده شود، جایی که امیدوارید LLM بر روی دادههای مرتبط کافی آموزش دیده باشد تا پاسخی رضایت بخش ارائه دهد.
یکی دیگر از ترفندها برای بهبود خروجی LLM، اضافه کردن چند مثال در Prompt و تبدیل آن به یک تنظیم چند نمونهای است.
from langchain import PromptTemplate, FewShotPromptTemplate
examples = [
{"word": "happy", "antonym": "sad"},
{"word": "tall", "antonym": "short"},
]
example_template = """
Word: {word}
Antonym: {antonym}\n
"""
example_prompt = PromptTemplate(
input_variables=["word", "antonym"],
template=example_template,
)
few_shot_prompt = FewShotPromptTemplate(
examples=examples,
example_prompt=example_prompt,
prefix="Give the antonym of every input",
suffix="Word: {input}\nAntonym:",
input_variables=["input"],
example_separator="\n",
)
few_shot_prompt.format(input="big")کد فوق الذکر یک الگوی Prompt تولید میکند و بر اساس مثالهای ارائه شده و ورودی، Prompt زیر را ترکیب میکند:
Give the antonym of every input Word: happy Antonym: sad Word: tall Antonym: short Word: big Antonym:
Chains: ترکیب LLMs با سایر اجزا
Chaining در LangChain، فرآیند ترکیب LLM ها با سایر مولفه ها برای ساخت یک برنامه را توصیف مینماید. برخی از مثالها عبارتند از:
ترکیب LLM ها با الگوهای Prompt (بخش قبل را ببینید)
ترکیب چندین LLM به ترتیب با استفاده از خروجی LLM اول به عنوان ورودی LLM دوم (بخش قبل را ببینید)
ترکیب LLM ها با دادههای خارجی، مانند پاسخ به سوالات (بخش Indexes را ببینید)
ترکیب LLM ها با حافظه بلند مدت، برای مثال برای تاریخچه چت (بخش memory را ببینید)
در بخش قبل، یک الگوی پارامتر ایجاد کردیم. هنگام استفاده از آن با LLM خود، میتوانیم از LLMChain به شکل زیر استفاده کنیم:
rom langchain.chains import LLMChain
chain = LLMChain(llm = llm,
prompt = prompt)
# Run the chain only specifying the input variable.
chain.run("colorful socks")
اگر میخواهیم خروجی این LLM را به عنوان ورودی LLM دوم استفاده کنیم، میتوانیم از SimpleSequentialChain استفاده کنیم:
from langchain.chains import LLMChain, SimpleSequentialChain
# Define the first chain as in the previous code example
# ...
# Create a second chain with a prompt template and an LLM
second_prompt = PromptTemplate(
input_variables=["company_name"],
template="Write a catchphrase for the following company: {company_name}",
)
chain_two = LLMChain(llm=llm, prompt=second_prompt)
# Combine the first and the second chain
overall_chain = SimpleSequentialChain(chains=[chain, chain_two], verbose=True)
# Run the chain specifying only the input variable for the first chain.
catchphrase = overall_chain.run("colorful socks")

Indexes: دسترسی به داده های خارجی
یکی از محدودیتهای LLM ها عدم دسترسی به اطلاعات متناسب (مثلا دسترسی به سند یا ایمیل خاصی) است. میتوانید با ارائه دادن دسترسی LLM ها به دادههای خارجی با این محدودیت مقابله کنید.
برای این منظور، ابتدا باید با یک بارگذاریکننده سند، دادههای خارجی را بارگیری کنید. LangChain بارگذاریکنندههای مختلفی را برای انواع مختلف اسناد از PDF و ایمیل تا وب سایتها و ویدئوهای یوتیوب فراهم میکند.
بیایید دادههای خارجی را از یک ویدیوی یوتیوب بارگیری کنیم. در صورت تمایل به بارگیری یک سند متنی بزرگ و تقسیم آن با یک جداساز متن، میتوانید به مستندات رسمی مراجعه کنید.
# pip install youtube-transcript-api
# pip install pytube
from langchain.document_loaders import YoutubeLoader
loader = YoutubeLoader.from_youtube_url("https://www.youtube.com/watch?v=dQw4w9WgXcQ")
documents = loader.load()حال که دادههای خارجی خود را به عنوان اسناد آماده دارید، میتوانید آن را با استفاده از یک مدل Embedding متنی (برای مشاهده مدلها مراجعه کنید) در پایگاه داده برداری – VectorStore – شاخص گذاری کنید. پایگاه داده برداری معروف عبارتند از Pinecone، Weaviate و. Milvus در این بخش از Faiss استفاده خواهیم کرد زیرا برای آن نیازی به کلید API نیست.
# pip install faiss-cpu from langchain.vectorstores import FAISS # create the vectorestore to use as the index db = FAISS.from_documents(documents, embeddings)
حالا سند شما (در این مورد، یک ویدیو) به عنوان Embeddings در پایگاه داده ذخیره شده است. میتوانیم از این دادههای خارجی برای انجام کارهای مختلف همچون پرسش و پاسخ از طریق بازیاب اطلاعاتی (information retriever) استفاده کنیم:
from langchain.chains import RetrievalQA
retriever = db.as_retriever()
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
return_source_documents=True)
query = "What am I never going to do?"
result = qa({"query": query})
print(result['result'])خروجی:

Memory: یادآوری گفتگوهای گذشته
برای برنامه هایی مانند چت بات ها، حافظه بلند مدت حیاتی است تا بتوانند گفتگوهای قبلی را به یاد بیاورند. با این حال، به طور پیش فرض، مدل های زبانی بزرگ هیچ حافظه بلند مدتی ندارند مگر اینکه تاریخچه چت را وارد کنید.

LangChain این مشکل را با ارائه چندین گزینه مختلف برای مدیریت تاریخچه چت حل میکند:
- نگهداری تمام گفتگوها،
- نگهداری آخرین k گفتگو،
- خلاصه کردن گفتگو.
در این مثال، از زنجیره گفتگو (ConversationChain) برای ارائه حافظه گفتگویی به این برنامه استفاده خواهیم کرد.
from langchain import ConversationChain conversation = ConversationChain(llm=llm, verbose=True) conversation.predict(input="Alice has a parrot.") conversation.predict(input="Bob has two cats.") conversation.predict(input="How many pets do Alice and Bob have?")
بدون استفاده از زنجیره گفتگو برای نگهداری حافظه گفتگویی، گفتگو شبیه به بخش چپ تصویر بالا خواهد بود. با استفاده از زنجیره گفتگو، گفتگوی راست تصویر بالا به دست خواهد آمد که شامل حافظه گفتگویی است.
Agents: دسترسی به سایر ابزارها
با وجود اینکه LLM ها قدرتمند هستند، اما محدودیتهایی نیز دارند: آنها اطلاعات زمینهای (مانند دسترسی به دانش خاصی که در داده های آموزشی موجود نیست) را ندارند، میتوانند به سرعت قدیمی شوند (برای مثال GPT-4 بر روی داده های قبل از تاریخ مشخصی آموزش دیده است) و در محاسبات ریاضی ناکارآمد (مثال) هستند.
LLM ها ممکن است قادر به انجام یک سری وظایف نباشند، از این رو باید به آنها دسترسی به ابزارهای تکمیلی مانند جستجو (مانند جستجوی گوگل)، ماشین حساب (مانند Python REPL یا Wolfram Alpha) و جستجوها (مانند ویکیپدیا) داده شود.
علاوه بر این، ما نیازمند عامل هایی هستیم که بر اساس خروجی LLM، تصمیماتی درباره استفاده از ابزارهای مختلف برای انجام وظایف مورد نظر بگیرند.
در زیر یک مثال آورده شده است که در آن عامل ابتدا تاریخ تولد باراک اوباما را با استفاده از ویکیپدیا جستجو کرده و سپس با استفاده از یک ماشین حساب، سن وی را در سال ۲۰۲۲ محاسبه می کند.
# pip install wikipedia
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.agents import AgentType
tools = load_tools(["wikipedia", "llm-math"], llm=llm)
agent = initialize_agent(tools,
llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True)
agent.run("When was Barack Obama born? How old was he in 2022?")
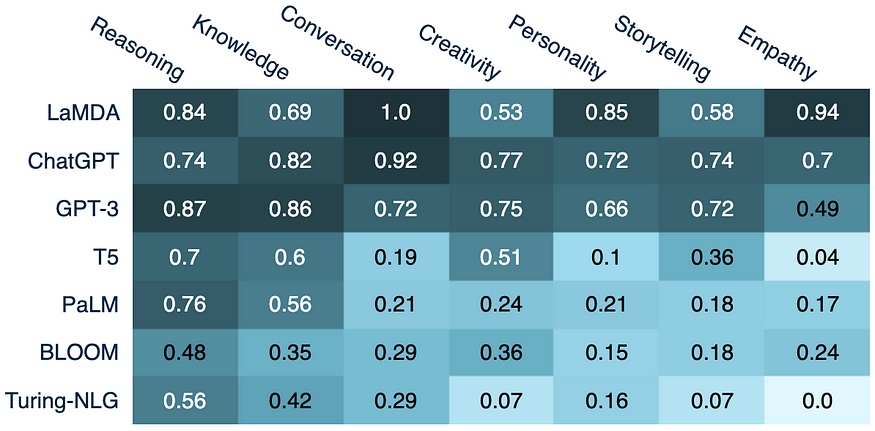
مقایسه LLMs مختلف
جمع بندی
با رونمایی ChatGPT همه یا حداقل بسیاری از افراد، تحت تأثیر قابلیتهای آن قرار گرفتند. اکنون، ابزارهای جدید توسعه دهندگان مانند LangChain افراد را قادر میسازد تا در عرض چند ساعت نمونههای اولیه چشمگیری را روی لپتاپهای خود ایجاد نمایند.
LangChain یک کتابخانه Python اپن سورس است که برای هر فردی که قادر به کدنویسی باشد، ساخت برنامه های مبتنی بر LLM را امکان پذیر می سازد. این پکیج یک رابط عمومی برای بسیاری از مدلهای پایه ارائه میکند، مدیریت Prompt را امکانپذیر میکند و به عنوان یک رابط مرکزی برای سایر کامپوننت ها مانند الگوهای Prompt، سایر LLMها، دادههای خارجی و سایر ابزارها از طریق agent ها عمل میکند.
این کتابخانه ویژگی های بسیار بیشتری نسبت به آنچه در این مقاله تحت عنوان آموزش کار با LangChain ذکر شد ارائه می دهد.

مهندس رضا استادی
مدیرعامل شرکت دانش بنیان فن آوران گیتی افروز


