جهت کسب اطلاع در مورد رودمپ عمومی هوش مصنوعی روی لینک رو به رو کلیک کنید.
ماشین بردار پشتیبان
فهرست محتوا:

ماشین بردار پشتیبان چیست؟
ماشین های بردار پشتیبان یا SVM) support vector machines)، یک دسته از الگوریتمهای یادگیری ماشین ساده و در عین حال قدرتمند هستند که برای طبقهبندی و رگرسیون استفاده میشوند. در این بحث، ما به استفاده از ماشین های بردار پشتیبان برای طبقهبندی میپردازیم.
با مرور مبانی طبقهبندی و ابر صفحه هایی که کلاسها را از هم جدا میکنند، شروع می شود و در نهایت به ماشین های بردار پشتیبان و پیاده سازی الگوریتم در scikit-learn میرسیم.
مسئله طبقهبندی و ابرصفحه های جداکننده
طبقهبندی، زمانی یک مسئله یادگیری با نظارت است که در آن دادههای برچسبدار داریم و هدف الگوریتم یادگیری ماشین، پیشبینی برچسب یک داده جدید است.
برای سادگی، بهتر است یک مسئله طبقهبندی دودویی با دو کلاس A و B در نظر بگیریم و نیاز داریم یک ابر صفحه پیدا کنیم که این دو کلاس را از هم جدا کند.
به صورت ریاضی، ابر صفحه یک فضای زیر مجموعه است که بعد آن یک واحد کمتر از فضای محیطی است. این بدان معنی است که اگر فضای محیطی یک خط باشد، ابر صفحه یک نقطه است. و اگر فضای محیطی یک صفحه دو بعدی باشد، ابرصفحه، یک خط است و به همین ترتیب.
بنابراین، زمانی که یک ابر صفحه دو کلاس را جدا میکند، دادههای متعلق به کلاس A در یک طرف ابر صفحه قرار دارند و دادههای متعلق به کلاس B طرف دیگر ابر صفحه قرار میگیرند. بنابراین، در فضای یک بعدی، ابر صفحه جدا کننده، یک نقطه است:
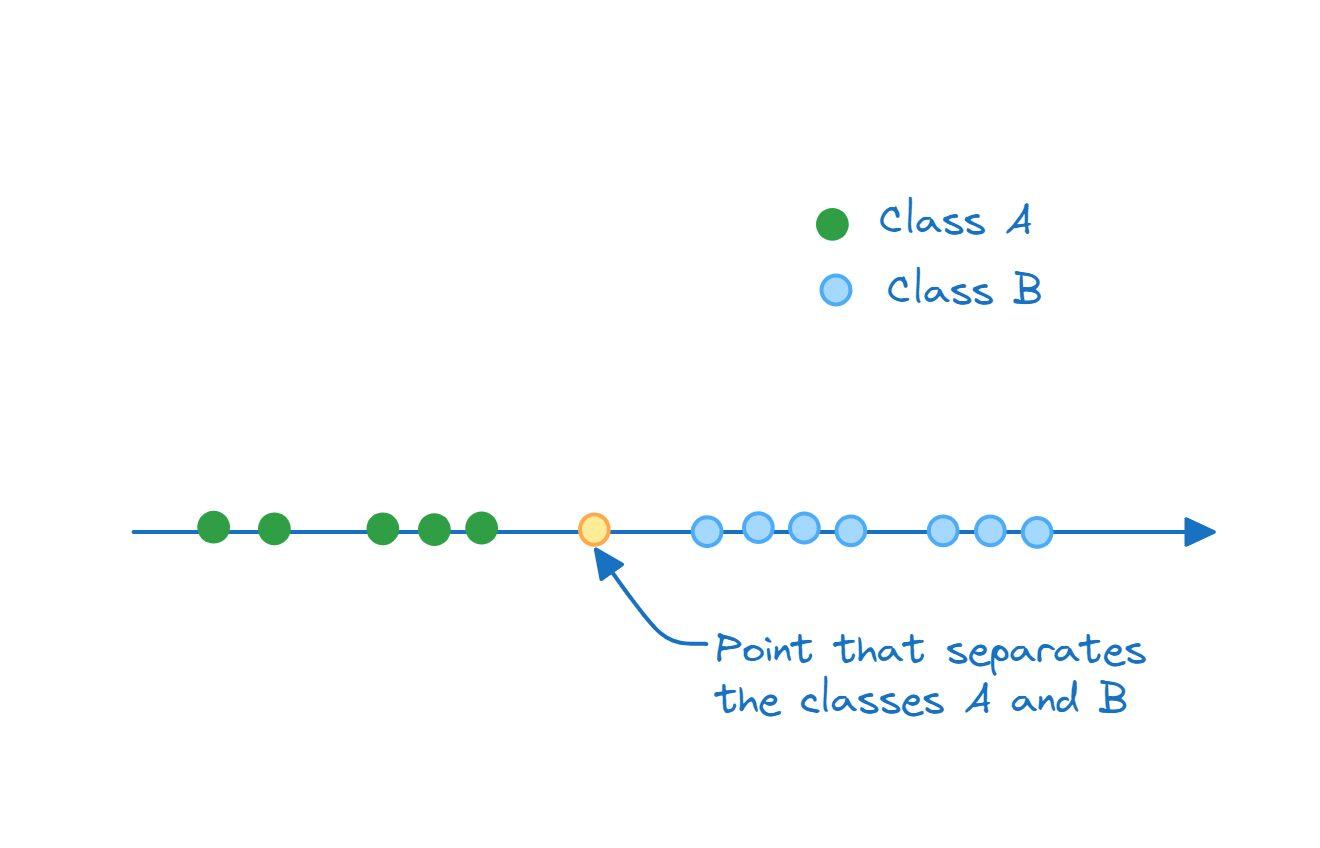
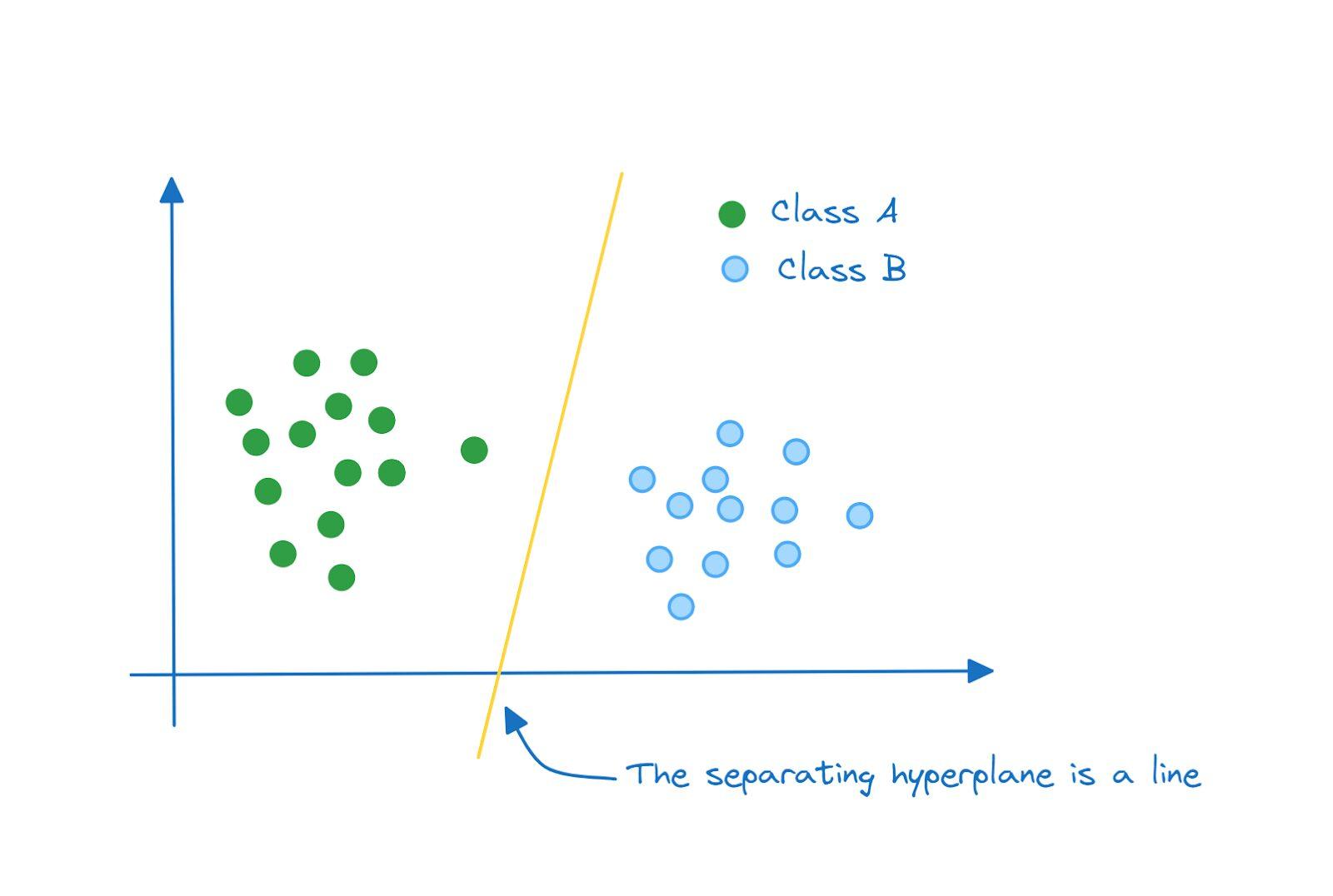
در فضای دو بعدی، ابر صفحه که کلاس A و B را از هم جدا میکند، یک خط است:
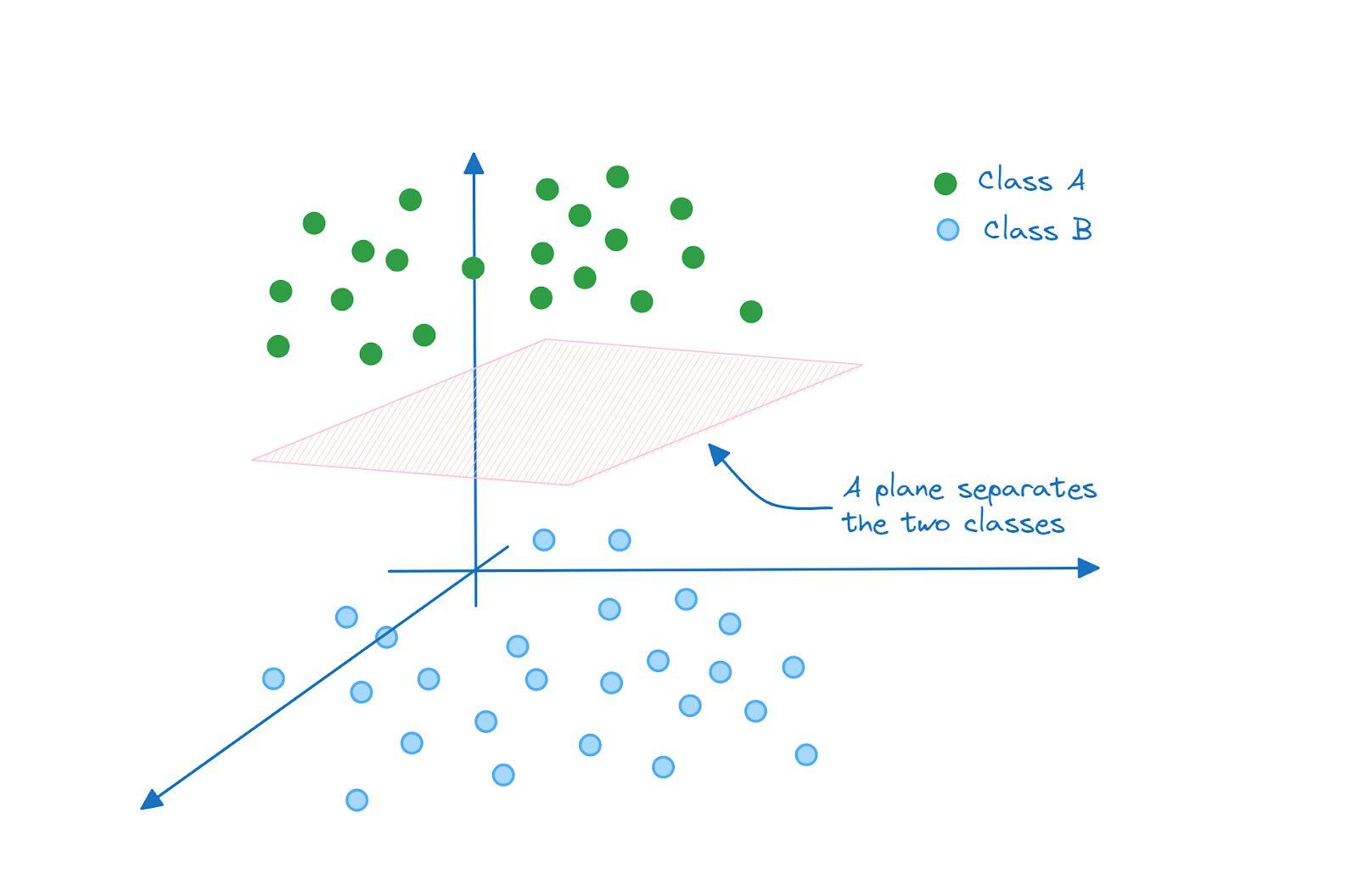
و در فضای سه بعدی، ابرصفحه هایی که کلاس A و B را از هم جدا میکند، یک صفحه است:
- بطور مشابه، در فضای N بعدی، ابر صفحه جداکننده، یک زیرفضای (N-1) بعدی است.
- اگر به نمونه فضای دو بعدی نگاهی دقیقتر بیندازید، هر یک از موارد زیر، یک ابرصفحه معتبر است که کلاس A و B را از هم جدا میکند:
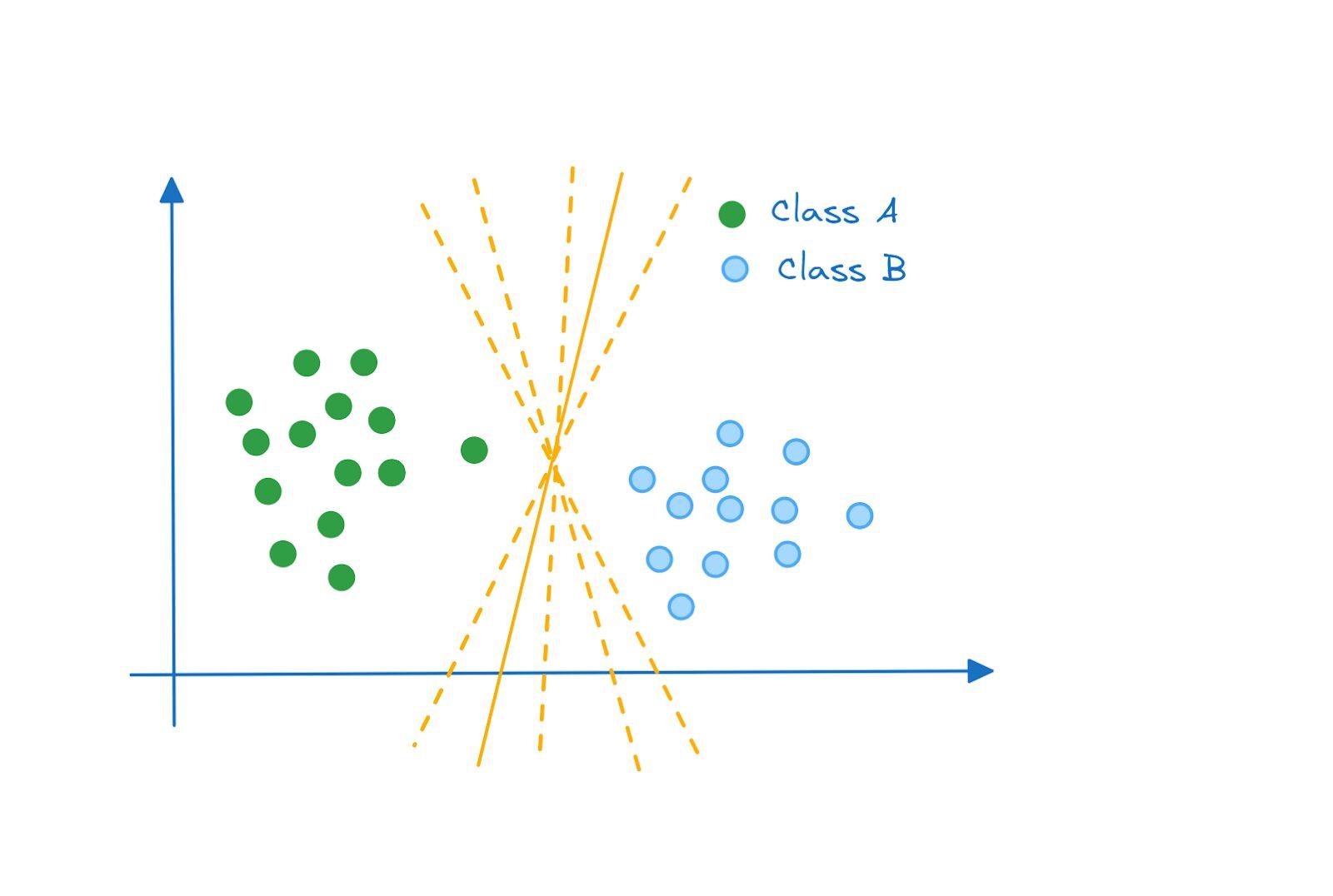
پس چگونه تصمیم میگیریم کدام ابرصفحه بهینه ترین است؟
پاسخ، طبقهبندی کننده بیشینه حاشیه (Maximum Margin Classifier) میباشد.
طبقهبندی کننده بیشینه حاشیه (Maximum Margin Classifier)
ابرصفحه بهینه، ابرصفحه ای است که دو کلاس را از هم جدا میکند و همچنین حاشیه بین آنها را نیز حداکثر می کند. طبقهبندی کنندهای که به این شکل عمل میکند، به عنوان طبقهبندی کننده بیشینه حاشیه نامیده میشود.
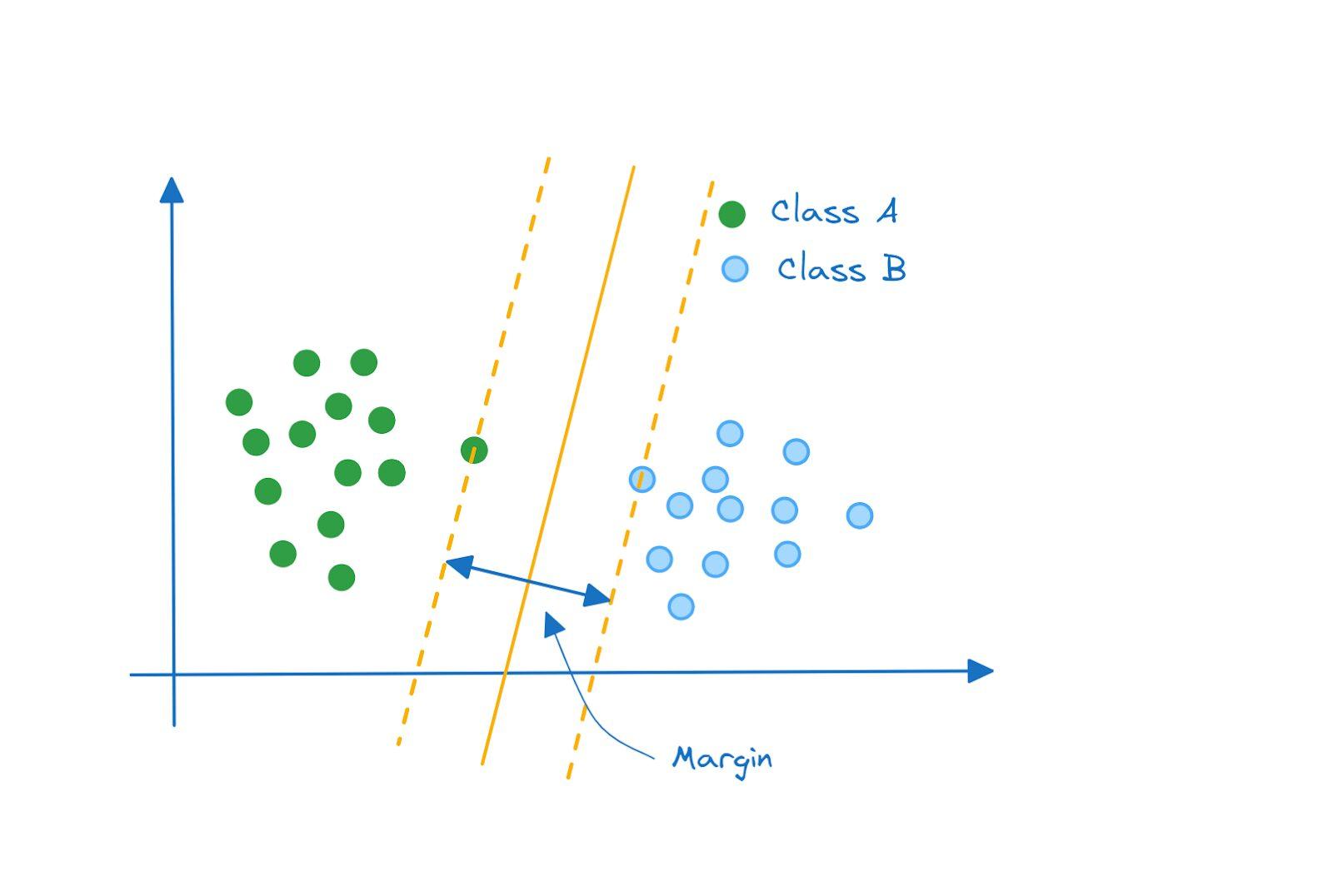
ابرصفحه بهینه، ابرصفحه ای است که دو کلاس را از هم جدا میکند و همچنین حاشیه بین آنها را نیز حداکثر می کند. طبقهبندی کنندهای که به این شکل عمل میکند، به عنوان طبقهبندی کننده بیشینه حاشیه نامیده میشود.
حاشیه سخت و حاشیه نرم
یک مثال بسیار ساده و ایدهآل در نظر گرفتیم که کلاسها به صورت کامل قابل تفکیک بودند و طبقهبندی کننده بیشینه حاشیه یک گزینه خوب برای آن بود.
اما اگر دادههای شما مانند این شکل توزیع شده باشد چه؟ کلاسها هنوز هم به صورت کامل توسط یک ابر صفحه، قابل جداسازی هستند و ابر صفحه ای که حاشیه را بیشینه میکند، به این شکل خواهد بود:
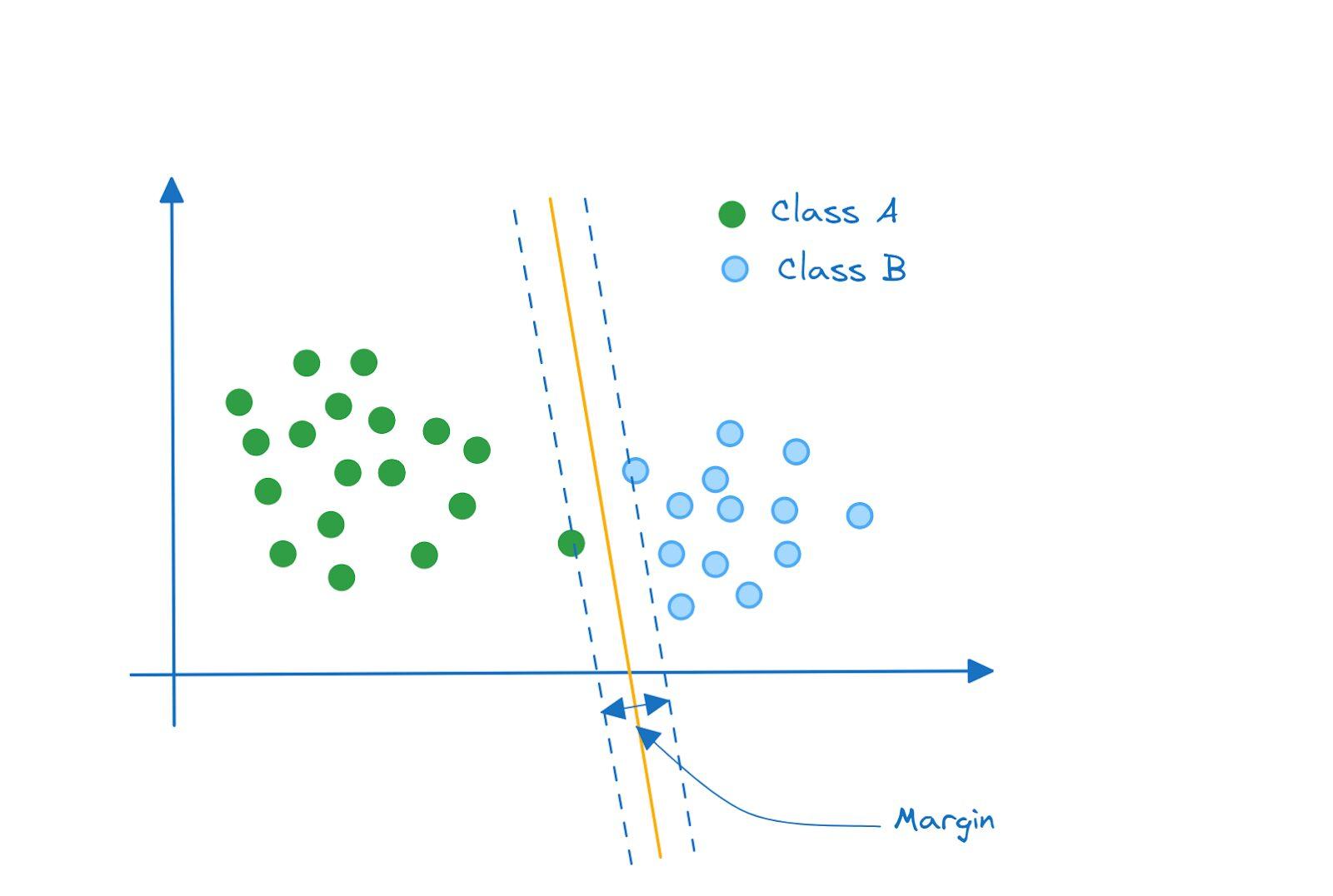
اما آیا مشکل این رویکرد را متوجه شدید؟
خب، هنوز هم جداسازی کلاسها انجام شده است. با این حال، این یک مدل با واریانس بالا است که شاید سعی در بسیار خوب بودن نقاط کلاس A دارد.
به علاوه، توجه کنید که حاشیه، هیچ داده اشتباها طبقه بندی شده ای ندارد. این نوع طبقهبندیکننده را طبقهبندی کننده حاشیه سخت مینامند.
به جای آن، به این طبقهبندیکننده نگاه کنید. آیا چنین طبقهبندیکنندهای بهتر عمل نمیکند؟ این یک مدل با واریانس به مراتب کمتر است که برای طبقهبندی نقاط کلاس A و B به خوبی عمل میکند.
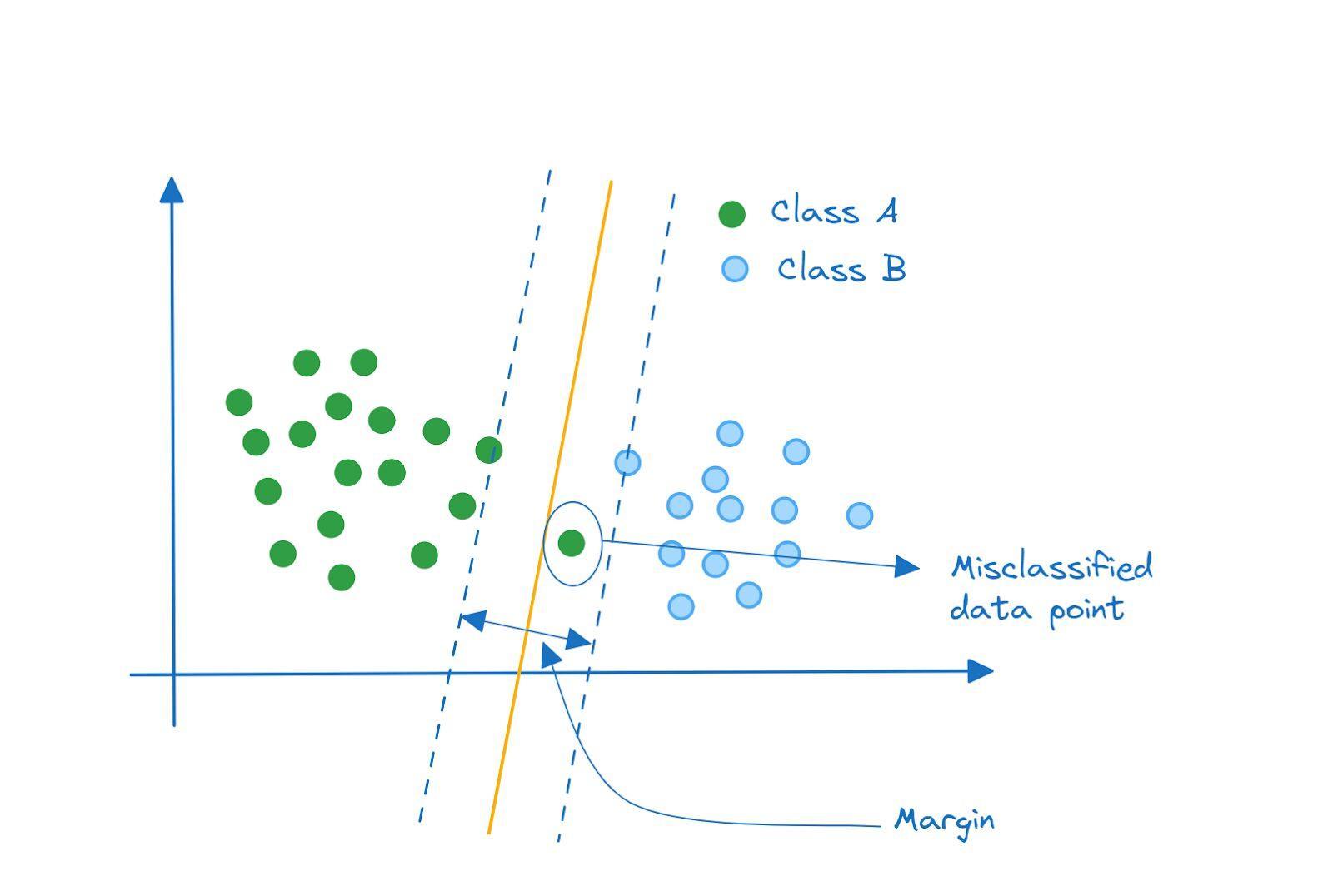
طبقهبندیکننده بردار پشتیبان
طبقهبند حاشیه نرمی که داریم، یک طبقهبند بردار پشتیبان خطی است. نقاط با یک خط (یا یک معادله خطی) قابل تفکیک هستند.
هر نقطه داده، یک بردار در فضای ویژگی است. نقاط دادهای که نزدیکترین به ابرصفحه جداکننده هستند، به عنوان بردارهای پشتیبان شناخته میشوند زیرا در طبقهبندی کمک میکنند.
همچنین جالب است بدانید که اگر یک نقطه داده یا زیرمجموعهای از نقاط داده را که بردار پشتیبان نیستند، حذف کنید، ابرصفحه جداکننده تغییر نمیکند. اما اگر یک یا چند بردار پشتیبان را حذف کنید، ابرصفحه تغییر خواهد کرد.
تا اینجا، نقاط داده به صورت خطی قابل جداسازی بودند، بنابراین ما میتوانستیم با کمترین خطا، یک طبقهبند حاشیه نرم برای آنها بسازیم. اما اگر نقاط داده به شکل زیر توزیع شده باشند چه؟
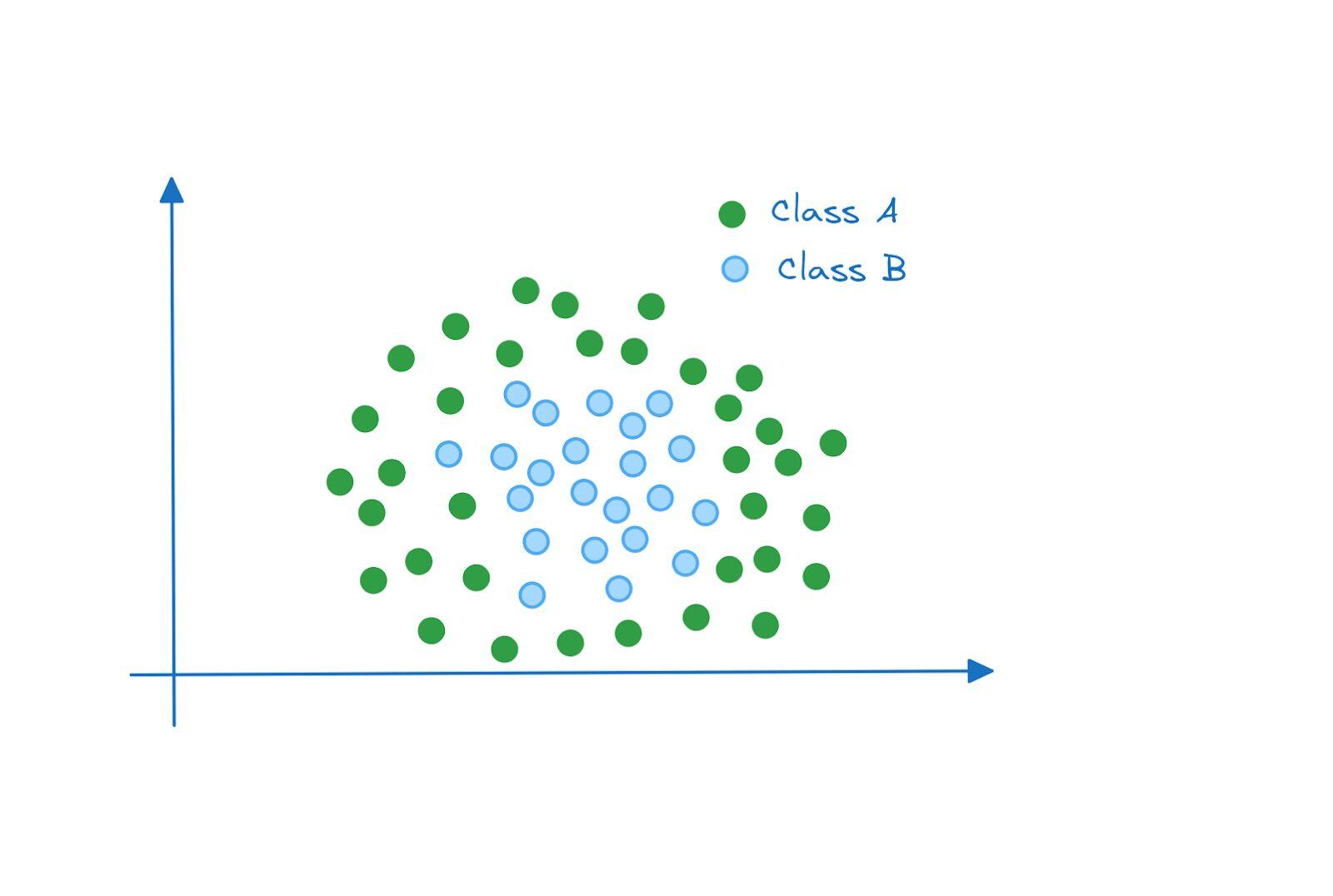
در این مثال، نقاط داده به صورت خطی قابل جداسازی نیستند. حتی اگر یک طبقهبند حاشیه نرم با مجاز بودن به خطا در طبقهبندی را داشته باشیم، ما قادر نخواهیم بود یک خط (ابرصفحه جداکننده) پیدا کنیم که عملکرد خوبی در این دو کلاس داشته باشد.
پس حالا چه کار باید انجام دهیم؟
ماشین بردار پشتیبان (SVM) و تنظیم کرنل
- مشکل: نقاط داده به صورت خطی قابل جداسازی در فضای ویژگی اصلی نیستند.
- راهحل: نقاط را بر روی یک فضای ویژگی با بعد بالاتر که در آن بصورت خطی قابل جداسازی هستند، انتقال دهید.
اما انتقال دادن نقاط بر روی یک فضای ویژگی با بعد بالاتر، نیازمند نقشهبرداری نقاط از فضای ویژگی اصلی به فضای با بعد بالاتر است. این محاسبات نیازمند زمان بیشتری برای انجام هستند، به خصوص زمانی که فضایی که میخواهیم نقشه برداری کنیم، از بعد بسیار بالاتری نسبت به فضای ویژگی اصلی باشد. در اینجا هسته (kernel) به کمک ما میآید.
طبقهبند حاشیهای بردار پشتیبان را میتوان با معادله زیر نمایش داد:
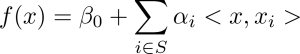

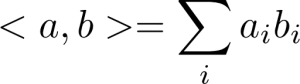

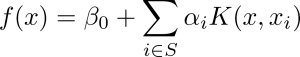
تابع هسته به غیرخطی بودن نقاط داده در فضای ویژگی اصلی توجه میکند. همچنین، این تابع به ما این امکان را میدهد که محاسبات را بر روی نقاط دادهای در فضای ویژگی اصلی انجام دهیم، بدون این که نیاز به محاسبه مجدد در فضای با بعد بالاتر داشته باشیم.
برای طبقهبند حاشیهای پشتیبان خطی، تابع هسته به سادگی ضرب داخلی است و شکل زیر را دارد:
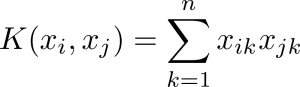
بردار پشتیبان تصمیم در Scikit-Learn
حال که مفهوم پشتیبانی از ماشین را درک کردیم، بیایید یک مثال سریع با استفاده از کتابخانه Scikit-Learn بنویسیم.
ماژول svm در کتابخانه Scikit-Learn شامل پیادهسازی کلاسهایی مانند LinearSVC ،SVC و NuSVC است. این کلاسها برای طبقهبندی دودویی و چند دستهای استفاده میشوند. مستندات گسترده Scikit-Learn لیست هستههای پشتیبانی شده را مشخص میکند.
ما از مجموعه داده داخلی wine استفاده خواهیم کرد (این دیتاست جزو دیتاست های معروف بوده و به راحتی قابل دسترس است از جمله در کتابخانه Scikit-Learn). این یک مسئله طبقهبندی است که در آن ویژگیهای wine برای پیشبینی برچسب خروجی که یکی از سه کلاس 0، 1 یا 2 است، استفاده میشود. این مجموعه داده، شامل حدود 178 رکورد و 13 ویژگی است.
مرحله ۱ - وارد کردن کتابخانه های مورد نیاز و فراخوانی مجموعه داده:
ابتدا، مجموعه داده wine را که در ماژول datasets کتابخانه Scikit-Learn قابل دسترسی است، می خوانیم:
این دستور، مجموعه داده wine را به صورت یک شیء باز میگرداند. این شیء شامل ماتریس ویژگیها و برچسبهای متناظر با آنها است. به عنوان مثال، برای دسترسی به ماتریس ویژگیها، میتوانید از کد زیر استفاده کنید:
from sklearn.datasets import load_wine
Load the wine dataset#
()wine = load_wine
X = wine.data
y = wine.target
مرحله ۲ - تقسیم مجموعه داده به دو بخش آموزش و تست
مجموعه داده را به دو بخش آموزش و تست تقسیم می کنیم. در اینجا، از یک نسبت تقسیم 80 به 20 استفاده میکنیم که 80 درصد و 20 درصد نقاط داده در مجموعه داده آموزش و تست قرار میگیرند:
from sklearn.model_selection import train_test_split
Split the dataset into training and test sets#
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=10)
مرحله ۳ - پیشپردازش مجموعه داده:
سپس، ما مجموعه داده را پیشپردازش میکنیم. ما از StandardScaler برای تبدیل نقاط داده به یک توزیع با میانگین صفر و واریانس یک استفاده میکنیم:
Data preprocessing#
from sklearn.preprocessing import StandardScaler
()scaler = StandardScaler
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
در اینجا، ما از تابع StandardScaler از Scikit-Learn برای تبدیل نقاط داده استفاده کردهایم. ابتدا، یک شیء از کلاس StandardScaler ایجاد میکنیم، سپس با استفاده از تابع fit_transform، ماتریس ویژگیهای داده آموزش را تبدیل میکنیم تا دارای میانگین صفر و واریانس یک شود. به عبارت دیگر، ماتریس ویژگیهای داده آموزش به دست آمده، نقاط داده را در فضای ویژگیهای جدیدی قرار میدهد. سپس با استفاده از تابع transform، ماتریس ویژگیهای داده آزمون را به فضای ویژگیهای جدید تبدیل میکنیم.
به یاد داشته باشید که از تابع fit_transform بر روی مجموعه داده تست استفاده نکنید زیرا این باعث مشکل ایجاد مشکل در داده ها میشود.
مرحله ۴ - ساخت یک ردهبند SVM و آموزش آن با دادههای آموزش:
در این مثال، ما از ردهبند SVC استفاده میکنیم. شیء svm را به عنوان یک شیء SVC ایجاد میکنیم و آن را با دادههای آموزش برازش میکنیم:
from sklearn.svm import SVC
Create an SVM classifier#
()svm = SVC
Fit the SVM classifier to the training data#
svm.fit(X_train_scaled, y_train)
در اینجا، ما از تابع SVC از Scikit-Learn برای ایجاد یک ردهبند SVM خطی با پارامتر C برابر با 1 استفاده کردهایم. سپس، این طبقه بندی کننده را با استفاده از تابع fit به دادههای آموزش، آموزش میدهیم.
مرحله ۵- پیشبینی برچسبها برای نمونههای آزمون:
برای پیشبینی برچسبهای کلاس برای دادههای تست، میتوانیم از متد predict روی شیء svm استفاده کنیم:
Predict the labels for the test set#
y_pred = svm.predict(X_test_scaled)
در اینجا، ما با استفاده از متد predict روی شیء svm برچسبهای کلاس را برای دادههای آزمون پیشبینی میکنیم و آنها را در متغیر y_pred ذخیره میکنیم.
مرحله ۶ - ارزیابی دقت مدل:
برای خلاصه بحث، ما فقط امتیاز دقت را محاسبه میکنیم. اما همچنین میتوانیم گزارش دقیق تر طبقهبندی و ماتریس اشتباهات را دریافت کنیم.
برای محاسبه این معیارهای ارزیابی، ما از توابع classification_report و confusion_matrix از Scikit-Learn استفاده میکنیم:
from sklearn.metrics import accuracy_score
Calculate the accuracy of the model#
accuracy = accuracy_score(y_test, y_pred)
print(f”{accuracy=:.2f}”)
Print confusion matrix#
print(confusion_matrix(y_test, y_pred))
Output >>> accuracy=0.97
تابع classification_report، گزارش دقیقی از معیارهای طبقهبندی مانند دقت، بازخوانی و F1 را ارائه میدهد. تابع confusion_matrix، ماتریس اشتباهات بین برچسبهای پیشبینی شده و برچسبهای واقعی را به صورت یک آرایه نشان میدهد.
کد کامل:
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
Load the wine dataset#
()wine = load_wine
X = wine.data
y = wine.target
Split the dataset into training and test sets#
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=10)
Data preprocessing#
from sklearn.preprocessing import StandardScaler
()scaler = StandardScaler
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
Create an SVM classifier#
()svm = SVC
Fit the SVM classifier to the training data#
svm.fit(X_train_scaled, y_train)
Predict the labels for the test set#
y_pred = svm.predict(X_test_scaled)
Calculate the accuracy of the model#
accuracy = accuracy_score(y_test, y_pred)
print(f”{accuracy=:.2f}”)
Print confusion matrix#
print(confusion_matrix(y_test, y_pred))
ما یک ردهبند ساده بردار پشتیبان داریم. پارامترهایی وجود دارند که میتوانید آنها را تنظیم کنید تا کارایی طبقه بندی کننده بردار پشتیبان را بهبود بخشید. پارامترهای معمولی که تنظیم میشوند شامل ثابت تنظیم C و مقدار گاما هستند.